1 背景
为了提升用户对文本的准确理解,我们设计并实现了一个多音字与易读错字标注系统。通过上传Word文档,程序将自动检测文中的多音字和易错字,并为其添加拼音注释。输出的结果会以Word文件形式返回,注释信息会在字词后以圆括号形式标注,方便用户阅读和展示。
2 目的
通过训练双向LSTM模型、逻辑回归、g2pM、调用大模型API等方法实现对文本的多音字和易读错字标注。
通过Django框架实现在线系统,方便用户通过网页上传和下载文档,实现实时检测与注音。
3 系统实现框架
3.1 前端
用户通过网页上传Word文档。
然后向后端接口发起POST请求,返回处理结果。
// 处理文档
function DealDoc(e){
// 处理选项
var radios = document.querySelector('input[name="gender"]:checked').value;
reader = document.getElementById("input").value
document.getElementById("output").value = "Loading...";
var url = 'https://nlp.bithao.com.cn/deal';
// 发起POST请求
fetch(url, {
method: 'POST',
headers: {
'Accept': 'application/json',
'Content-Type':'application/x-www-form-urlencoded'
},
body: `input=${reader}&radios=${radios}`
})
.then(response => response.json())
.then(data => {
console.log('Success:', data);
// 显示输出结果
document.getElementById("output").value = data.result;
})
.catch(error => {
console.error('Error:', error);
});
}用户点击下载,将处理好的数据保存为docx文件,直接在客户端完成,无需占用服务端资源。
3.2 后端
view层,数据处理接口,根据不同选项以Json格式返回不同方法的处理结果。
def deal(request):
if request.method == 'POST':
data = request.POST["input"]
radios = int(request.POST["radios"])
if radios == 1: # LSTM
result = LSTMDealDoc(data)
elif radios == 2: # 逻辑回归
result = LGDealDoc(data)
elif radios == 3: # g2pm
result = g2pmDealDoc(data)
elif radios == 4: # 大模型
result = AIDealDoc(data)
content = {
"result": result
}
return JsonResponse(content)4 双向LSTM模型
功能-BiLSTM
双向长短时记忆网络(BiLSTM)在多音字消歧中的应用,主要是因为它具备从两个方向(前向和后向)处理序列数据的能力。具体来说,BiLSTM 相比于单向的 LSTM 可以更好地处理语言中的依赖关系,因为它不仅能够考虑到多音字前面的词语(前向信息),还能够结合后续的词语(后向信息)来做出判断。这种双向处理使得模型在消岐时能够利用更多的上下文信息,从而更准确地确定多音字的正确读音。
4.1 数据来源
一、汉字拼音库,使用《现代汉语词典》中的拼音数据,汉字数:11017,多音字个数:1217;
(来自pinyin-data)
二、人民日报1988年一月的新闻语料,一共有19374条新闻,包含5593个多音字,其中有85种不同的多音字;来自(pkuopendata)
4.2 数据预处理
数据统计:
- 统计了多音字的读音个数,了解多音字的分布情况。
- 对新闻语料中的多音字进行统计,包括出现次数和含多音字的句子数量等。
- 对短语中的多音字进行统计和分析。
语料划分:
将语料划分为训练集、验证集和测试集。
train.csv(训练集,29928 条短语,30041 个多音字)
valid.csv(验证集,8723 条短语,12696 个多音字)
test.csv(测试集,8638 条短语,19198 个多音字)
数据预处理:
- 使用 torchtext 库对文本进行处理。
- 对句子和读音进行 tokenize(分词),建立词典。
- 设定 batch size 和生成迭代器,以便将数据送入模型进行训练。
4.3 模型搭建
仿照词性标注问题的分类方法:
1. 仿照词性标注的处理思路,将训练数据编码为特定格式,其中 “NA” 代表非多音字,多音字则使用读音来编码。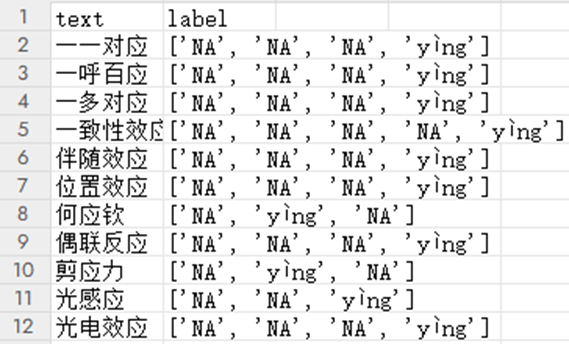
2. 已将短语数据送入模型并进行训练,然后使用测试集计算准确率,将标注正确的语句和标注错误的语句输出到相应文件中(correct.csv 和 wrong.csv)。
# 用于消岐的神经网络
class DisambiguationLSTM(nn.Module):
def __init__(self, n_word, word_dim, word_hidden, n_pronounce):
super(DisambiguationLSTM, self).__init__()
self.word_embedding = nn.Embedding(n_word, word_dim)
self.lstm = nn.LSTM(
input_size=word_dim,
hidden_size=word_hidden,
num_layers=configure.num_layer,
batch_first=True,
bidirectional=True
)
self.linear1 = nn.Linear(word_hidden*2, n_pronounce)
def forward(self, x):
x = self.word_embedding(x)
x, _ = self.lstm(x)
x = x.squeeze(0)
x = self.linear1(x)
return x3. 使用optuna库寻找最优参数;
#寻找最优参数
import optuna
def objective(trial):
trn_rate = trial.suggest_float('trn_rate', 0.4, 0.8)
val_rate = trial.suggest_float('val_rate', 0.1, 0.4)
batch_size = trial.suggest_categorical('batch_size', [256, 512, 1024])
num_layer = trial.suggest_int('num_layer', 1, 3)
# 更新配置中的参数
configure.trn_rate = trn_rate
configure.val_rate = val_rate
configure.batch_size = batch_size
old_acc = 0
......
4.4 word文档注音
假设已经有了一个处理 Word 文档并进行多音字注音的函数 annotate_word_document,其思路如下:
4.4.1 易读错字
除多音字外,还要求程序能够识别易读错字。通过网络信息检索获得400个易错字词,包括容易平翘舌不分、前后鼻音不分、h/f不分、鼻边音不分等难点发音字词,轻声儿化等需变调词语,以及一部分较生僻的字,例如摈(bìn)弃、疮(chuāng)疤、舂(chōng)等等。程序运行时,直接从目标文章中识别并注音即可。
1. 读取 Word 文档内容,将其转换为文本并导入易错字,多音字JSON词典;
def word_doc_to_text(file_path):
doc = docx.Document(file_path)
text = ""
for paragraph in doc.paragraphs:
text += paragraph.text
return text
#读取约400个易错字,注意csv编码格式为UTF-8
def read_mispronounced_words(file_path):
df = pd.read_csv(file_path)
return dict(zip(df['text'], df['label']))
# 读取多音字 JSON 文件
with open('../data/polyphones.json', 'r', encoding='utf-8') as f:
polyphone_data = json.load(f)
polyphone_list = list(polyphone_data.keys())
2. 使用jieba对文本进行分词,得到单词列表。
3. 对于每个单词,判断是否包含多音字:
def is_word_contain_polyphone(word):
for char in word:
if char in polyphone_list:
return True
return False
4. 分词词语转化为适配模型输入的张量,并根据模型输出确定读音;
#分词词语转化为模型输入的张量,进行预处理,如填充和截断def word_to_tensor(word, vocab):
word_index = vocab.stoi.get(word, vocab.stoi['<unk>'])
return torch.tensor(word_index).unsqueeze(0)
def words_to_tensor_list(word_list, vocab, max_length):
tensor_list = [word_to_tensor(word, vocab) for word in word_list]
padded_tensor_list = torch.nn.utils.rnn.pad_sequence(tensor_list, batch_first=True)
if len(padded_tensor_list) > max_length:
return padded_tensor_list[:max_length]
else:
return padded_tensor_list
def determine_pronunciation(output, label_vocab):
# 根据模型输出确定读音
predicted_label_index = torch.argmax(output).item()
pronunciation_label = label_vocab.itos[predicted_label_index]
# 根据标注体系,提取读音信息并返回
if pronunciation_label == "NA": #NA表示非多音字
word = label_vocab.itos[predicted_label_index]
if word in mispronounced_words: #如果是易错字词,返回读音
return mispronounced_words[word]
else:
return ""
else:
return pronunciation_label
5. 如果单词包含多音字,使用训练好的LSTM模型进行预测,如果模型能够确定读音,则在单词中的多音字后面标注读音;如果模型未识别,则使用多音字JSON文件中的读音信息进行标注,如果单词不包含多音字,直接添加到结果中;
整体思路是通过对不同来源的数据进行统计和预处理,搭建多音字消歧模型,并将其应用于 Word 文档的多音字注音任务中。在模型搭建过程中,尝试了不同的方法,并选择了较为有效的仿照词性标注问题的分类方法进行训练和测试。
验证集上准确率达到85-90%,测试集准确率为75%-88%
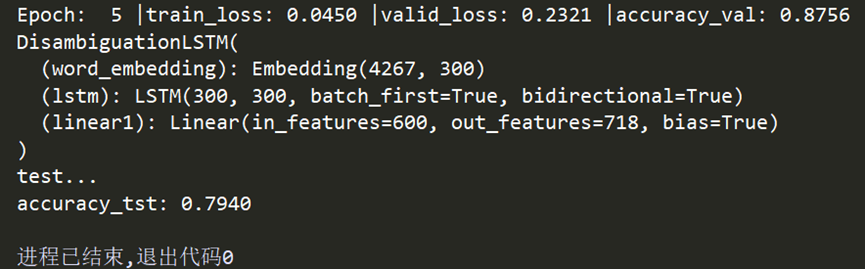
4.4.2 模型改进-其他词性
由于训练语料库主要由短语或词语构成,将多音字消歧模型应用于长文本时,短语级别的训练限制了模型对更复杂语境中多义词的判断,无法充分利用句子或段落中的全局上下文信息。例如“的”作为助词时在长文本中及其常见,但在训练短语中仅出现67次,且不少作为固定短语,如“狗娘养的”、“一矢中的”。
为了改进模型,考虑通过识别常见的副词、助词、方位词、连词和介词中的多音字,并根据长文本上下文判断词性,再在原有模型基础上对这些字进行二次注音。不同词性下,某些多音字的发音是固定的,因此可以利用这一点进行二次注音,降低模糊性。此外,词性判断依赖于上下文,可以有效地利用句子和段落级别的信息,而不是仅依赖于短语。
以副词为例,常见的副词包括“非常、绝对、极度、十分、最、顶级、太、更、极其、格外、分外、一直、才、总 、也、都、全部、总体、总共、共、统统、又、仅仅、只、光、一概 、已经、曾经、早已、刚刚、正、正在、就、就要、将、将要、曾、刚、才、在 、不、非、没、没有、不用(甭)、必、必须、必定、准、的确、未、别、忽然、猛然、公然、特意、亲自、大肆、肆意、难道、决、岂、反正、也许、大约、大概、果然、居然、竟然、究竟 、家、这里、那里、每一处、楼”,其中包含多音字的有以下几个,且作为副词时读音固定,分别是“才(cái)、都(dōu)、将(jiāng)、没(méi)”。同理,手工找出常见助词、方位词、连词和介词中的多音字。最后汇总的这些词性的多音字一共有17个,分别为
副词:才(cái)、都(dōu)、将(jiāng)、没(méi)
助词:了(le)、着(zhe)、过(guo)、地(de)、的(de)、得(de)
方位词:中(zhōng)
介词:从(cóng)、当(dāng)、为(wèi)、给(gěi)
连词:和(hé)、便(biàn)
使用jieba库的pseg模块,对长文本进行分词及词性标注,并对上述特定词性的多音字二次标注。代码示例如下:
import jieba.posseg as pseg
# 定义要加注音的字及其拼音
pinyin_dict = {
'才': 'cái',
'都': 'dōu',
'将': 'jiāng',
'没': 'méi',
'了': 'le',
'着': 'zhe',
'过': 'guo',
'地': 'de',
'的': 'de',
'得': 'de',
'中': 'zhōng',
'从': 'cóng',
'当': 'dāng',
'为': 'wèi',
'给': 'gěi',
'和': 'hé',
'便': 'biàn'
}
# 定义目标词性集合(副词、助词、方位词、介词、连词)
target_pos = {'d', 'p', 'f', 'c', 'uv', 'ul', 'uj'}
# 处理句子的函数
def add_pinyin(sentence):
words = pseg.cut(sentence) # 使用 jieba 分词并获取词性
result = []
for word, flag in words:
if word in pinyin_dict and flag in target_pos:
result.append(f"{word}({pinyin_dict[word]})") # 如果满足条件,添加拼音注释
else:
result.append(word) # 否则直接保留原字
return ''.join(result)
# 示例
text = "才知道,你在雨中飞快地跑,我走了。"
# 输出加注音的句子
annotated_text = add_pinyin(text)
print(annotated_text)
# words = pseg.lcut(text)
# 打印每个词及其词性
# for word, flag in words:
# print(f"{word}: {flag}")4.5 模型评估
输入输出案例:

5 逻辑回归
功能-逻辑回归
主要思想:
把多音字注音分解为每个多音字的读音识别,即分解为六百多个简单分类任务。利用多音字在不同句子中的词性,及其前后词语的词性作为特征训练模型,得到六百多个模型。使用的时候从前到后遍历word文档,如果遍历到多音字字典里的字,则调用对应的模型进行预测。
数据集:
CPP (Chinese Polyphones with Pinyin)
https://paperswithcode.com/dataset/cpp
拥有99000条中文多音字数据,数据格式如下:
| 用▁标记多音字的句子 | 正确读音 |
|---|---|
| 斯考尔将她救出,并搭乘遗弃的星际飞船回到▁了▁星球。 | Le5 |
项目流程:
- 处理数据:
79100条作为训练集,9800条作为验证集,10250条作为测试集。
利用THULAC进行分词,经处理得到如下训练输入和输出:
| 输入 | 输出 | |||
|---|---|---|---|---|
| 多音字所在词 | 前面词的词性 | 所在词的词性 | 后面词的词性 | 正确读音 |
| 了 | v | u | n | Le5 |
- 训练模型:
将输入输出数据进行编码后进行训练。
# 训练模型并评估验证集
for epoch in range(10): # 假设我们进行10个epoch的训练
model.fit(X_train_encoded, y_train_encoded)
y_val_pred_encoded = model.predict(X_val_encoded)
accuracy_val = accuracy_score(y_val_encoded, y_val_pred_encoded)
# 如果验证集表现更好,保存当前的最佳模型
if accuracy_val > best_accuracy:
best_accuracy = accuracy_val
best_model = model
# 保存最佳模型和编码器
if best_model:
model_save_path = os.path.join(folder_path, 'best_model.pkl')
encoder_save_path = os.path.join(folder_path, 'encoders.pkl')
joblib.dump(best_model, model_save_path)
joblib.dump({'onehot_encoder': onehot_encoder, 'label_encoder': label_encoder}, encoder_save_path)- 测试结果:
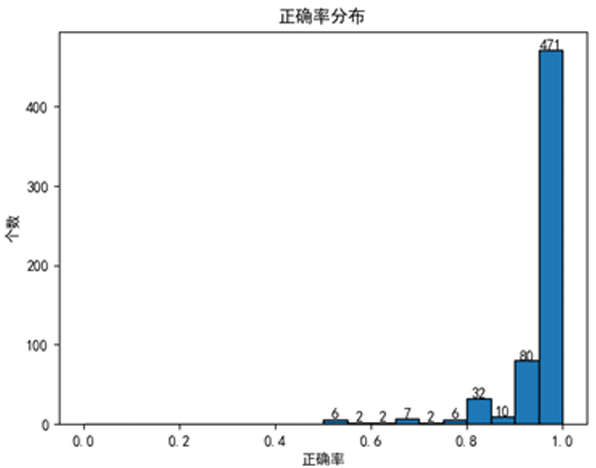
该数据集部分多音字只标注了一个读音。综合正确率等于整体预测正确数目除以预测条数。
如果默认只有一个注音的多音字都预测正确:在测试集上综合正确率97.14%
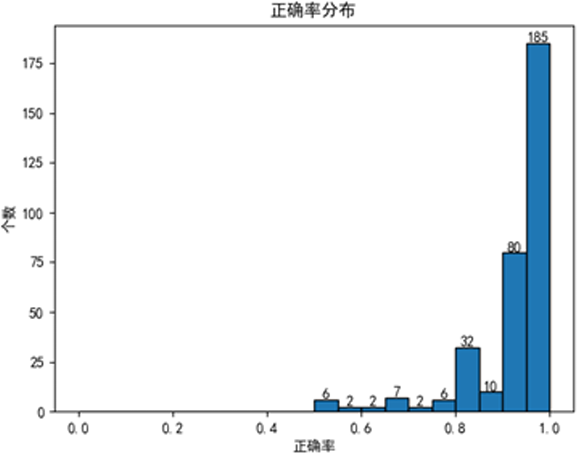
如果不考虑只有一个注音的多音字,综合正确率为94.81%
写文档针对性进行测试效果如下图:

分析总结:
逻辑回归训练的模型在测试集上表现较好,但是实际应用效果比较一般。分析可能有如下几点原因:
- 数据集同一个字的不同读音数据量失衡。
- 部分多音字不同发音所组成的词用法区别不大,无法有效通过词性进行判断。
该方法实现起来比较简单,且对训练设备要求不高。但是这个方法只是浅显的通过词性训练,且每个字各有一个模型,没有建立理解语义的大模型。
6 g2pm
功能-g2pm
G2pM使用方法:
from g2pM import G2pM
model = G2pM()
sentence = "输入要注音的文本"
Pinyin=model(sentence, tone=True, char_split=False)- 创建多音字字典文档
- 输入word文档,裁剪文本利用G2pM模型识别
- 处理返回的拼音数据,只截取多音字的注音并按要求输出word文档
效果展示:

7 大模型API调用
功能-大模型
这里选择Kimi大模型,通过添加提示词,让AI返回结果。
from openai import OpenAI
client = OpenAI(
api_key = "sk-########################################",
base_url = "https://api.moonshot.cn/v1",
)
history = [
{"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}
]
def chat(query, history):
history.append({
"role": "user",
"content": query
})
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=history,
temperature=0.3,
)
result = completion.choices[0].message.content
history.append({
"role": "assistant",
"content": result
})
return result
def MakeBiaozhu(input_data):
output_data = f"你是一位骨灰级国语大师,对下面段落文字中多音字、易读错字,加上注音,放在圆括号内,不需要做出任何解释:'{input_data}'"
return output_data
def AIDealDoc(input_doc):
return chat(MakeBiaozhu(input_doc), history)输入输出案例:

本方法调用大模型API做垂直领域的应用是可行的,但效果依赖于提示词的使用,同时成本较高。
Comments NOTHING