作业:词向量训练
一、 实验目的
- 掌握课堂所讲词向量的基本概念和训练方法。
- 加强对pytorch、tensorflow等深度学习框架的使用能力。
二、 实验要求
请写明选择的词向量模型结构(可以参考课程PPT,也可以自由选择一些主流的论文中提到的模型)
三、 任务说明
请使用任意一种深度学习框架(推荐pytorch),利用给定的语料训练词向量即可,中文和英文都需要训练,中文语料位于data文件夹下的zh.txt中,已经分好词。英文语料位于data文件夹下的en.txt中。(给定的语料规模较小,如果有充足的计算资源,也可自己选用更大的语料来训练,但需在报告中写明)。
四、 实验过程
1、模型选择
skip-gram模型,输入是一个词汇,输出则是该词汇的上下文。
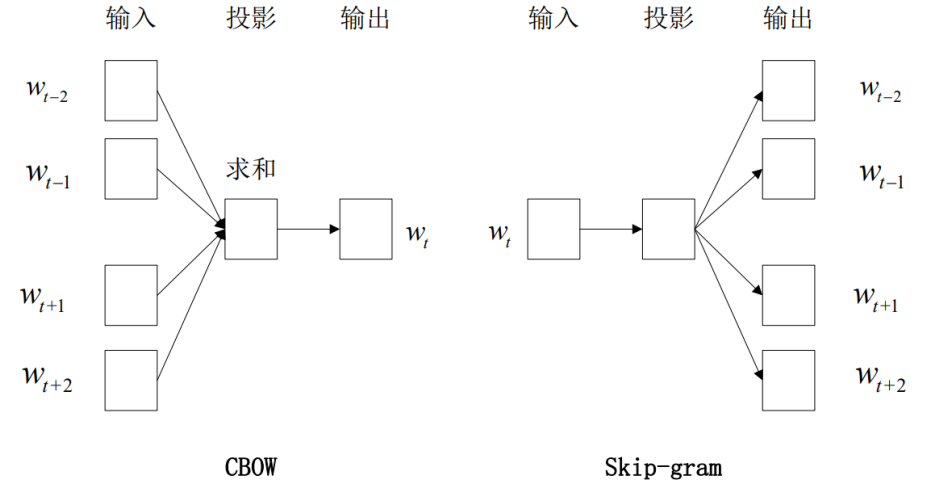
2、模型超参数
| 参数 | 值 | 说明 |
|---|---|---|
| MAX_VOCAB_SIZE | 80000 | 词典中单词地个数 |
| K | 100 | 负样本地个数 |
| C | 2 | 附近单词地门限 |
| NUM_EPOCHS | 5 | 训练轮数 |
| LEARNING_RATE | 0.5 | 初始学习率 |
| EMBEDDING_SIZE | 100 | 词向量特征地个数 |
| BATCH_SIZE | 16 | 批大小 |
3、数据预处理
空格分割读取的数据,如果是中文数据需过滤停用词,选择常用地MAX_VOCAB_SIZE个单词作为词典,不常用地词统一用unk表示。
def load_stop_words(file_stopwords):
"""
加载停用词
"""
with open(file_stopwords, "r", encoding="utf-8") as f:
return f.read().split("n")
def dataPreprocess(file, iszh):
"""
数据预处理
:param iszh: 是否为中文
:return:
"""
if iszh:
stop_words = load_stop_words(file_stopwords)
with open(file, 'r', encoding="utf-8") as f:
text = f.read()
text = text.split() # 空格分割
text = list(filter(lambda word: word not in stop_words, text)) # 过滤停用词
else:
with open(file) as f:
text = f.read()
text = text.split() # 空格分割
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)) # 选择常用地MAX_VOCAB_SIZE个单词
vocab['<unk>'] = len(text) - np.sum(list(vocab.values())) # 不常用地词统一用unk表示
return text, vocab4、模型结构
使用灵活得方式去定义模型,继承nn.Module类。
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
# 初始化输入和输出得embedding
super(EmbeddingModel, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
# 初始化
initrange = 0.5 / self.embed_size
self.out_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.out_embed.weight.data.uniform_(-initrange, initrange)
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.in_embed.weight.data.uniform_(-initrange, initrange) # 这是在范围直接均匀分布采样
def forward(self, input_labels, pos_labels, neg_labels):
"""
input_labels:中心词,[batch_size]
pos_labels:中心词周围context window 出现过得单词[batch_size * (window_size * 2)]
neg_labels:中心词周围没有出现过得单词,从negative sampling得到[batch_size, (window_size*2*K)]
return:loss,[batch_size]
"""
batch_size = input_labels.size(0)
input_embedding = self.in_embed(input_labels) # batchsize*embed_size
pos_embedding = self.out_embed(pos_labels) # batchsize*(2*c)*embed_size
neg_embedding = self.out_embed(neg_labels) # batchsize*(2*c*k)*embed_size
# 计算损失
input_embedding = input_embedding.unsqueeze(2) # [batchsize, embed_size, 1]
log_pos = torch.bmm(pos_embedding, input_embedding).squeeze() # [batchsize, 2*C]
log_neg = torch.bmm(neg_embedding, -input_embedding).squeeze() # [batchsize, 2*c*100]
log_pos = F.logsigmoid(log_pos).sum(1)
log_neg = F.logsigmoid(log_neg).sum(1)
loss = log_pos + log_neg
return -loss
def input_embedding(self):
return self.in_embed.weight.data.cpu().numpy()5、模型训练
训练步骤:前向传播,计算损失,梯度清零,反向传播,参数更新
def train(model):
"""
训练
:return:
"""
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
for epoch in range(NUM_EPOCHS):
pbar = tqdm(total=100, desc=f"epoch:{epoch}")
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
# 先保证都是longTensor
input_labels = input_labels.long()
pos_labels = pos_labels.long()
neg_labels = neg_labels.long()
if use_cuda:
input_labels = input_labels.cuda()
pos_labels = pos_labels.cuda()
neg_labels = neg_labels.cuda()
optimizer.zero_grad()
loss = model(input_labels, pos_labels, neg_labels).mean()
loss.backward()
optimizer.step()
pbar.update(100/len(dataloader))
pbar.close()6、模型测试
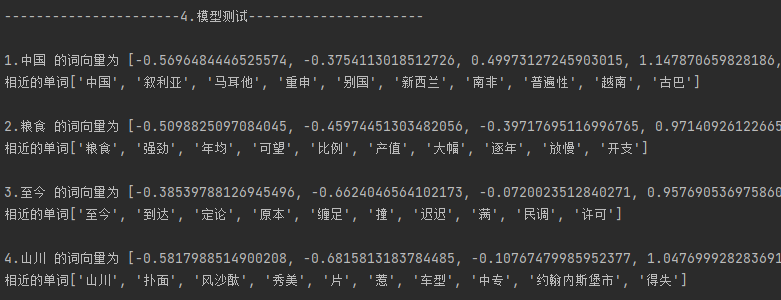
寻找距离最近的几个单词,看看训练得这个词向量矩阵得效果。
英文数据:['present', 'food', 'can', 'specifically']
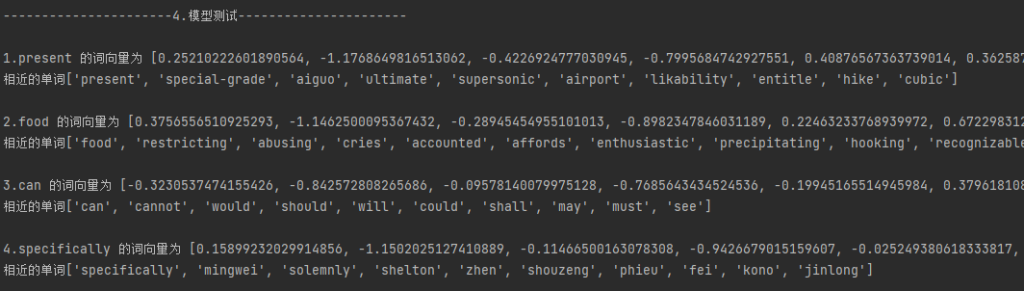
中文数据:['中国', '粮食', '至今', '山川']
Comments NOTHING