一、引言
1.1 研究背景与意义
股票市场作为经济的重要组成部分,其走势的准确预测一直是投资者、金融机构和研究者关注的焦点。股票价格受到众多复杂因素的影响,如宏观经济状况、公司财务状况、政策法规、行业竞争以及投资者情绪等。这些因素相互交织,使得股票市场具有高度的不确定性和波动性,给股票走势预测带来了巨大的挑战。传统的股票走势预测方法主要基于基本面分析和技术分析。基本面分析通过研究宏观经济数据、公司财务报表等信息,评估股票的内在价值,从而预测其价格走势。然而,基本面分析往往需要大量的专业知识和时间精力,且对宏观经济环境的变化较为敏感。技术分析则主要通过研究股票的历史价格和成交量等数据,运用各种技术指标和图表形态,来预测股票价格的未来走势。虽然技术分析在一定程度上能够捕捉到股票价格的短期波动规律,但对于长期趋势的预测能力相对有限。
深入研究情感分析在股票预测中的应用具有重要的理论与实践意义。一方面,从理论层面拓展了金融市场研究的边界,打破传统仅依赖基本面与技术面分析的局限,将投资者情绪这一主观因素纳入研究范畴,完善对金融市场价格形成机制的理解。另一方面,在实践中,能够为投资者提供更全面、精准的决策依据,辅助其制定科学合理的投资策略,降低投资风险,提高收益水平;同时,也有助于金融监管部门更好地把握市场情绪动态,及时察觉潜在的市场异常波动,维护金融市场的稳定与健康发展。近年来,随着互联网技术的飞速发展,社交媒体平台上涌现出了大量与股票相关的信息,如股吧中的股民讨论、分析师的评论等。这些信息中蕴含着丰富的投资者情感和市场情绪,为股票走势预测提供了新的视角。情感分析作为自然语言处理的一个重要分支,旨在通过对文本数据的分析,挖掘其中所表达的情感倾向和态度。将情感分析应用于股票市场,能够从投资者的情感角度出发,揭示市场情绪对股票价格的影响,从而为股票走势预测提供更全面的信息。本研究旨在结合LSTM(长短期记忆网络)和股吧情感分析,构建一种新的股票走势预测模型。通过对股吧文本数据进行情感分析,提取投资者的情感特征,并将其与股票的历史价格数据相结合,输入到LSTM模型中进行训练和预测。这种方法能够充分利用LSTM在处理时间序列数据方面的优势,以及情感分析所挖掘出的投资者情感信息,提高股票走势预测的准确性和可靠性。
1.2 相关研究工作
在股票走势预测领域,国内外学者进行了大量的研究工作。早期的研究主要集中在基本面分析和技术分析方法上,随着机器学习和深度学习技术的发展,越来越多的学者开始尝试运用这些技术来预测股票走势。如支持向量机(SVM)、神经网络(NN)、决策树等机器学习算法在股票预测中得到了广泛应用。这些算法在一定程度上提高了预测的准确性,但对于股票市场的复杂非线性关系和长期依赖关系的处理能力有限。为了更好地处理时间序列数据中的长期依赖问题,Hochreiter和Schmidhuber于1997年提出了LSTM模型。LSTM是一种特殊的循环神经网络(RNN),它通过引入门控机制,能够有效地解决传统RNN中存在的梯度消失和梯度爆炸问题,从而在时间序列预测任务中表现出优异的性能。研究表明,LSTM在处理基于时序数据的股票预测问题时性能优于RNN和传统的机器学习算法[1]。近年来,LSTM在股票走势预测中得到了越来越多的应用。一些研究将LSTM与其他技术相结合,如卷积神经网络(CNN)、注意力机制等,进一步提高了预测的准确性。
现有基于LSTM的股票预测模型主要通过分析文本信息的情感极性特征,如[2]使用了判断趋势是上升还是下降的方法。正面新闻往往会导致上升趋势,而负面新闻往往会导致下降趋势。将媒体新闻的情感极性与历史交易数据作为股票预测算法的输入,需要考虑的问题。财经新闻中的情感极性并不明显,大多是对客观事件的总结和报道,使得财经新闻的情感极性分析准确率并不高,影响股票走势的预测准确率。[3]提出一种基于CNN-BiLSTM多特征融合的股票走势预测模型,通过融入新闻事件类型和情感极性提高股票走势预测的准确率。一方面,采用从新闻报道中提取出客观的财经事件,如中标事件、上市事件、停牌事件等;另一方面,采用Bi-LSTM对新闻报道的情感极性进行分析,计算新闻文本的情感分值。通过预测两只个股(家电行业的格力电器和电子电器行业的中兴通讯)准确率比现有算法分别高出 11.6% 和 25.6%,表明新闻事件及其情绪取向可能导致股票价格波动。
随着社交媒体的兴起,股吧作为投资者交流和分享信息的重要平台,其中蕴含的投资者情感信息逐渐受到关注。一些学者开始将情感分析应用于股票市场,研究投资者情感与股票价格之间的关系。如Bollen等人通过对Twitter上的情感数据进行分析,发现投资者的情感倾向与股票市场的波动之间存在一定的相关性。本文通过对东方财富股吧的帖文进行情感分析,构建股市投资者情绪指数,将LSTM和股吧股民的情感分析相结合进行A股走势预测。
二、相关理论与技术
2.1 LSTM原理与优势
2.1.1 LSTM基本结构
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络(RNN),专为解决长序列数据中的长期依赖问题而设计。与传统RNN不同,LSTM通过引入门控机制和细胞状态,能够有效控制信息的流动和存储,从而更好地捕捉时间序列中的长期依赖关系。LSTM的核心结构是记忆单元(Memory Cell),它由一个或多个神经元组成,负责在整个序列处理过程中保持和更新长期依赖信息。记忆单元的状态通过时间步传递,并且仅通过线性方式更新,这使得它能够避免传统RNN中梯度消失或爆炸的问题。
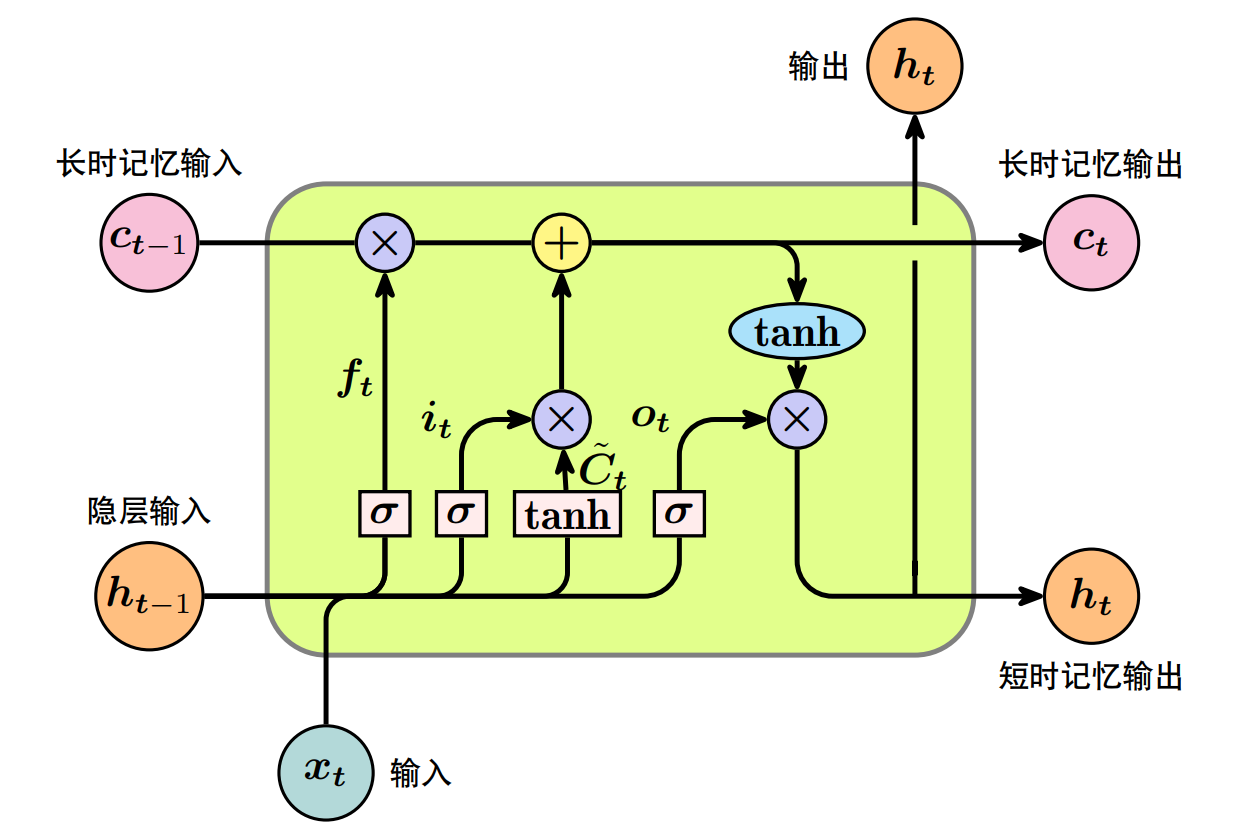
在LSTM中,门控机制起着关键作用,主要包括遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。遗忘门决定从记忆单元中丢弃哪些信息。它通过一个sigmoid函数生成一个0到1之间的值,表示每个状态值的保留程度。当遗忘门开启(激活值接近1)时,对应的记忆单元内容将被显著削弱甚至完全清除;当遗忘门关闭(激活值接近0)时,则相应信息得以保留。数学上,遗忘门的计算公式为:
$$
f_t = \sigma(W_f \cdot [h_{t - 1}, x_t] + b_f)
$$
其中,$f_t$是遗忘门在时间步$t$的输出,$sigma$是sigmoid函数,$W_f$是权重矩阵,$[h_{t - 1}, x_t]$是前一时间步的隐藏状态$h_{t - 1}$和当前时间步的输入$x_t$的拼接,$b_f$是偏置项。
当前时刻新输入信息哪些部分应被添加到记忆单元中。它由两部分构成:一个sigmoid层决定哪些值将被更新,一个tanh层生成新的候选值向量。输入门的sigmoid层和tanh层的输出相乘,得到更新后的候选值。输入门的计算公式为:
输入门决定
$$
i_t = \sigma(W_i \cdot [h_{t - 1}, x_t] + b_i)
$$
$$
\widetilde{C}_t = \tanh(W_c \cdot [h_{t - 1}, x_t] + b_c)
$$
其中,$i_t$是输入门在时间步$t$的输出,$\widetilde{C}_t$是候选记忆单元状态,$W_i$、$W_c$是权重矩阵,$b_i$、$b_c$是偏置项。
记忆单元状态更新是通过遗忘门的输出和输入门的输出相加得到的。这样可以确保网络能够记住重要的长期信息,并遗忘不相关的信息。记忆单元状态更新公式为:
$$
C_t = f_t \cdot C_{t - 1} + i_t \cdot \widetilde{C}_t
$$
其中,$C_t$是时间步$t$的记忆单元状态,$C_{t - 1}$是前一时间步的记忆单元状态。
输出门决定记忆单元状态的哪一部分将被输出到隐藏状态。它通过一个sigmoid层决定哪些单元状态将被输出,然后通过tanh层生成输出状态的候选值,最后将这两部分结合起来形成最终的输出。输出门的计算公式为:
$$
o_t = \sigma(W_o \cdot [h_{t - 1}, x_t]+ b_o)
$$
$$
h_t = o_t \cdot \tanh(C_t)
$$
其中,$o_t$是输出门在时间步$t$的输出,$h_t$是时间步$t$的隐藏状态,$W_o$是权重矩阵,$b_o$是偏置项。
2.1.2 处理时间序列数据的能力
在处理时间序列数据时,LSTM能够有效捕捉数据中的长期依赖关系,这是其相较于其他模型的显著优势。传统的RNN在处理长序列数据时,由于梯度消失或爆炸问题,很难学习到远距离的依赖信息。而LSTM通过门控机制和细胞状态,能够选择性地保留和更新信息,使得重要的信息能够在长时间内传播,从而准确捕捉时间序列中的长期依赖关系。例如,在股票价格预测中,股票价格的波动往往受到过去多个时间点的多种因素影响,这些因素之间的关系可能在较长时间内保持一定的稳定性。LSTM能够通过记忆单元和门控机制,记住过去重要的价格信息、市场情况以及投资者情绪等因素,并根据当前的输入信息对这些记忆进行更新和调整,从而更准确地预测未来的股票价格走势。具体来说,遗忘门可以根据当前信息决定是否遗忘过去的某些信息,输入门可以控制新信息的输入,而输出门则决定哪些信息将被输出用于当前的预测。这种机制使得LSTM能够在处理时间序列数据时,充分利用历史信息,提高预测的准确性。
2.2 股吧情感分析方法
股吧情感分析旨在从股吧中的文本数据中提取投资者的情感倾向,判断其对股票的看法是积极、消极还是中性。本实验采用snownlp库进行股吧情感分析。snownlp是一个基于Python的自然语言处理工具包,它提供了简单易用的情感分析功能。在snownlp中,情感分析是基于训练好的情感分类模型实现的。该模型通过对大量带有情感标签的文本数据进行训练,学习到文本中词语与情感倾向之间的关系。当输入一篇股吧文本时,snownlp首先对文本进行分词处理,将文本分割成一个个词语。然后,根据训练好的模型,计算每个词语的情感得分,并综合考虑整个文本中词语的情感得分,得出该文本的情感倾向。具体而言,snownlp会返回一个介于0到1之间的情感得分,得分越接近1表示文本的情感越积极,得分越接近0表示文本的情感越消极。例如,当分析一篇股吧帖子时,如果帖子中包含大量积极词汇,如"上涨" "利好" "看好"等,snownlp计算出的情感得分可能会较高,表明投资者对该股票持积极态度;反之,如果帖子中出现较多消极词汇,如"下跌" "利空" "看好"等,情感得分则会较低,反映出投资者的消极情绪。除了snownlp,文本情感分析还有其他常用技术。词袋模型(Bag-of-Words)是一种简单的文本表示方法,它将文本中的词语看作是一个无序的集合,忽略词语的顺序和语法结构。通过统计每个词语在文本中出现的频率,构建文本的特征向量,然后利用机器学习算法,如朴素贝叶斯、支持向量机等,对文本的情感进行分类。然而,词袋模型没有考虑词语之间的语义关系,可能会丢失一些重要信息。深度学习模型在情感分析中也得到了广泛应用,如循环神经网络(RNN)及其变体LSTM、门控循环单元(GRU),以及卷积神经网络(CNN)等。这些模型能够自动学习文本的特征表示,捕捉词语之间的上下文关系,从而提高情感分析的准确性。例如,基于LSTM的情感分析模型可以通过门控机制处理文本中的长距离依赖关系,更好地理解文本的语义和情感。不同的情感分析方法各有优缺点,在实际应用中需要根据具体情况选择合适的方法或结合多种方法来提高分析的准确性和可靠性。
三、A 股市场特点及趋势分析
3.1 2020 - 2025 年 A 股整体走势回顾
在 2020 年初,受新冠疫情全球爆发的影响,A 股市场经历了短暂的大幅下跌。随后,在各国政府出台的一系列经济刺激政策下,市场逐渐企稳回升。2020 年下半年至 2021 年上半年,A 股市场呈现出结构性牛市行情,部分行业板块(如新能源、半导体等)表现强劲,带动指数上涨。2021 年下半年至 2022 年,市场面临经济增速放缓、流动性收紧等压力,整体呈现震荡下行态势。2023 年,随着国内经济复苏预期增强,市场出现一定程度的反弹,但仍受到全球经济不稳定因素的影响,波动较大。2024 年,在政策利好不断释放的背景下,市场逐步回暖,部分优质股票表现突出。到 2025 年初,市场延续了复苏的趋势,但不同板块之间的分化依然明显。
3.2 影响 A 股市场走势的因素
- 宏观经济因素:国内生产总值(GDP)增速、通货膨胀率、利率水平等宏观经济指标对 A 股市场走势有着重要影响。例如,GDP 增速的提高通常预示着企业盈利的增加,会推动股票价格上涨;而利率上升则会增加企业的融资成本,对股票市场形成压力。
- 政策因素:货币政策和财政政策的调整会直接影响市场的资金面和企业的经营环境。宽松的货币政策会增加市场流动性,有利于股票价格上涨;积极的财政政策如加大基础设施建设投资,会带动相关行业的发展,提升企业的盈利预期。
- 行业发展因素:不同行业在不同时期的发展前景和竞争格局差异较大。新兴行业如人工智能、生物医药等,由于具有较高的成长性和创新能力,往往受到市场的青睐,股票价格表现较好;而传统行业如钢铁、煤炭等,可能会受到行业周期和市场竞争的影响,股价波动较大。
四、实验设计
本实验旨在探究 2020 - 2025年期间,结合 A 股市场数据与利用 snownlp 库对股吧评论进行情感分析的结果,对股票走势预测的有效性。
4.1 数据收集与整理
4.1.1 A股历史交易数据来源
本实验的A股历史交易数据来源于akshare金融数据接口库。akshare是一个基于Python的开源金融数据接口库,它提供了丰富的金融数据,包括股票、期货、基金、债券等市场的历史交易数据和实时行情数据。其优势在于数据获取方便、免费且数据更新较为及时。在本实验中,我们使用akshare的股票日线行情接口,获取了特定股票在一段时间内的历史交易数据,包括开盘价、收盘价、最高价、最低价、成交量和成交额等信息。具体代码如下:
import akshare as ak
e = {
"code": "000001",
"start": "20200113",
"end": "20250114"
}
df = ak.index_zh_a_hist(symbol=e["code"], period="daily", start_date=e["start"], end_date=e["end"])上述代码中,symbol参数指定了要获取数据的股票代码,start_date和end_date参数分别指定了数据的起始日期和结束日期。通过调用index_zh_a_hist函数,我们可以获取到该股票在指定时间范围内的日线行情数据,并将其存储在df数据框中。获取的数据格式如图:
4.1.2 股吧文本数据抓取
股吧文本数据的抓取通过编写Python爬虫程序实现。我们使用了requests库和BeautifulSoup库来发送HTTP请求并解析网页内容。具体步骤如下:
确定目标股吧网页的URL结构。例如,东方财富网股吧中某股票的讨论页面URL格式为https://gubaf10.eastmoney.com/list,zssh000001,f.html,其中000001为股票代码。
发送HTTP请求获取网页内容。使用requests.get()函数发送请求,并检查响应状态码以确保请求成功。代码如下:
import requests
from bs4 import BeautifulSoup
from headfile import *
def get_comment(page_numb=1):
"""
从股吧获取评论
:return: 评论列表
"""
# URL 地址
url = "https://gubaf10.eastmoney.com/list,zssh000001,f.html" if page_numb == 1 else f"https://gubaf10.eastmoney.com/list,zssh000001,f_{page_numb}.html"
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 发送请求
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 确保中文显示正确
# 解析 HTML
soup = BeautifulSoup(response.text, "html.parser")
# 提取评论部分
comments = soup.find("div", class_="all").find_all("div", class_="articleh")
result = [[], []]
# 遍历每条评论
for comment in comments:
# 提取标题
title_div = comment.find("span", class_="l3")
if title_div:
title = title_div.get_text(strip=True)
result[0].append(title)
time_div = comment.find("span", class_="l5")
if time_div:
time = time_div.get_text(strip=True)
result[1].append(time)
return result
if __name__ == '__main__':
# 2020-01-13到2025-01-13的评论
total_pages = [80, 55135]
comments = np.array([[], []])
for i in trange(total_pages[0], total_pages[1]):
comments_i = np.array(get_comment(page_numb=i))
comments = np.hstack((comments, comments_i))
df = pd.DataFrame(np.array(comments).T, columns=["评论", "时间"])
print(df.head())
df.to_csv(f"data\comments.csv")使用BeautifulSoup库解析网页内容,提取所需的评论文本和发表时间。通过分析网页的HTML结构,找到包含评论和时间信息的HTML标签和类名。例如,评论内容在<div class="articleh">标签内,发表时间在<span class="l5">标签内。代码如下:
为了获取更多的评论数据,需要遍历多页股吧网页。可以通过分析URL的页码参数,构造不同页码的URL并重复上述步骤。例如,第二页的URL为https://gubaf10.eastmoney.com/list,zssh000001,f_2.html。获取的数据格式如图:

4.1.3 数据预处理
股吧文本数据处理:对抓取的股吧文本数据进行去重,为每个评论按顺序添加相应的年份。
情感特征提取:在股吧文本数据方面,我们通过情感分析提取了情感特征。具体而言,我们为每个评论计算了情感得分,然后将每天的所有评论情感得分进行汇总,得到当天的情感特征。考虑到不同评论的重要性可能不同,我们选择了中位数作为当天情感得分的代表值。这是因为中位数能够减少极端值的影响,更稳健地反映整体的情感倾向。例如,如果某一天的评论中存在少数极端积极或消极的评论,使用中位数可以避免这些极端评论对整体情感判断的过度影响。
数据整合:将处理后的交易数据和股吧文本数据按照时间顺序进行整合。确保每个交易日都对应有相应的股吧评论情感数据。最终形成一个包含交易数据、股吧情感数据和标签的数据集。
通过上述方法,我们从交易数据和股吧文本数据中提取了丰富的特征,这些特征将作为模型的输入,用于训练和预测股票走势。
4.2 模型构建
4.2.1 LSTM模型架构设计
本实验构建的LSTM模型包含以下几个主要部分:
输入层:输入层接收经过预处理后的特征数据。输入参数包括输入特征维度input_size,数据形状(batch, seq_len, input_size),batch 是同时处理的序列数量,可根据硬件资源和数据规模调整;seq_len 是时间序列的长度,取决于所处理数据的时间跨度。在本实验中,我们设置时间步长为7,即考虑过去7天的历史数据。
LSTM层:我们使用了三层LSTM层,以增强模型对时间序列数据中复杂依赖关系的学习能力。隐藏层大小为32,LSTM层的隐藏层大小是一个重要的超参数,它决定了模型的学习能力和复杂度。通过实验和调优,我们发现这三个层数和隐藏层大小的设置能够在本实验数据集上取得较好的性能。模型代码如下:
class lstm(nn.Module):
def __init__(self, input_size=8, hidden_size=32, num_layers=3, output_size=1, dropout=0, batch_first=True):
super(lstm, self).__init__()
# lstm的输入 #batch, seq_len, input_size
self.hidden_size = hidden_size
self.input_size = input_size
self.num_layers = num_layers
self.output_size = output_size
self.dropout = dropout
self.batch_first = batch_first
self.rnn = nn.LSTM(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers,
batch_first=self.batch_first, dropout=self.dropout)
self.linear = nn.Linear(self.hidden_size, self.output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out, (hidden, cell) = self.rnn(x)
out = self.linear(hidden[-1])
out = self.sigmoid(out)
return out3. 全连接层:LSTM层的输出通过一个全连接层进行处理,将其映射到最终的输出维度。全连接层的作用是对LSTM层提取的特征进行进一步的整合和转换,以适应预测任务的要求。在本实验中,全连接层的输出维度为1,使用nn.Linear函数定义全连接层,代码如下:
self.linear = nn.Linear(self.hidden_size, self.output_size)输出层:输出层采用Sigmoid激活函数,将全连接层的输出转换为0到1之间的概率值,表示股票价格上涨的可能性。如果概率值大于0.5,则预测股票价格上涨,否则预测股票价格下跌。在PyTorch中,使用nn.Sigmoid函数定义输出层的激活函数,代码如下:
def forward(self, x):
out, (hidden, cell) = self.rnn(x)
out = self.linear(hidden[-1])
out = self.sigmoid(out)
return out4.2.2 数据划分
我们将数据集划分为训练集、验证集和测试集,其中训练集用于训练模型,验证集用于训练时验证模型,测试集用于评估模型的性能。
def getData(corpusFile, sequence_length, batchSize):
"""
获取数据
:param corpusFile:
:param sequence_length:
:param batchSize:
:return:
"""
df, close_max, close_min = dataPreprocessing(corpusFile) # 获取标准化后的数据和最大最小值
# 构造X和Y
# 根据前n天的数据,预测未来一天的收盘价(close)
sequence = sequence_length
X = []
Y = []
for i in range(df.shape[0] - sequence):
X.append(np.array(df.iloc[i:(i + sequence), ].values, dtype=np.float32))
Y.append(np.array(df.iloc[(i + sequence), 0], dtype=np.float32))
# 构建数据集划分
total_len = len(Y)
train_len = int(args.train_size * total_len) # 动态训练集比例
val_len = int(args.val_size * total_len) # 动态验证集比例
test_len = total_len - train_len - val_len # 动态测试集比例
# 划分训练集、验证集和测试集
trainx, trainy = X[:train_len], Y[:train_len]
valx, valy = X[train_len:train_len + val_len], Y[train_len:train_len + val_len]
testx, testy = X[train_len + val_len:], Y[train_len + val_len:]
# 创建DataLoader
train_loader = DataLoader(dataset=Mydataset(trainx, trainy, transform=transforms.ToTensor()),
batch_size=batchSize, shuffle=True)
val_loader = DataLoader(dataset=Mydataset(valx, valy),
batch_size=batchSize, shuffle=True)
test_loader = DataLoader(dataset=Mydataset(testx, testy),
batch_size=batchSize, shuffle=False)
return close_max, close_min, train_loader, val_loader, test_loader4.2.3 模型训练与优化
优化器选择:为了训练LSTM模型,我们选择了Adam优化器。Adam优化器是一种自适应学习率的优化算法,它能够根据每个参数的梯度自适应地调整学习率,从而在训练过程中更快地收敛到最优解。Adam优化器的优点是计算效率高、内存需求小,并且对不同类型的问题都有较好的适应性。代码如下:
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr) # Adam梯度下降 学习率=0.0001其中,model.parameters()表示需要优化的模型参数,lr为学习率,设置为0.001。学习率是一个重要的超参数,它决定了优化器在每次迭代中更新参数的步长。通过实验,我们发现0.001的学习率在本实验中能够取得较好的训练效果。
2. 损失函数选择:选择均方误差(Mean Squared Error)作为损失函数。均方误差损失函数是一种适用于回归任务的损失函数,通过计算预测值和真实值之间的平方差的平均值,为模型训练提供了一个可量化的优化目标。代码如下:
criterion = nn.MSELoss() # 定义损失函数模型训练:训练过程如下:
close_max, close_min, train_loader, val_loader, test_loader = getData(args.corpusFile, args.sequence_length, args.batch_size)
# 用于保存损失
train_losses = []
val_losses = []
for epoch in range(args.epochs):
model.train()
total_loss = 0
# 使用 tqdm 显示训练进度条
with tqdm(train_loader, desc=f'Epoch {epoch}/{args.epochs}', unit='batch') as pbar:
for idx, (data, label) in enumerate(pbar):
if args.useGPU:
data1 = data.squeeze(1).cuda()
pred = model(Variable(data1).cuda())
label = label.unsqueeze(1).cuda()
else:
data1 = data.squeeze(1)
pred = model(Variable(data1))
label = label.unsqueeze(1)
loss = criterion(pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
# 更新进度条的损失显示
pbar.set_postfix(loss=total_loss)
train_losses.append(total_loss) # 保存训练损失
# 每10个epoch保存一次模型
if epoch % 10 == 0:
torch.save({'state_dict': model.state_dict()}, args.save_file)在每个训练 epoch 中,首先将模型设置为训练模式,然后遍历训练数据加载器中的每个批次。在每个批次中,先将输入数据传入模型得到预测结果,然后计算损失值,再将优化器的梯度清零,反向传播更新参数。
五、实验结果与分析
训练参数如下:
# TODO 常改动参数
parser.add_argument('--gpu', default=0, type=int) # gpu 卡号
parser.add_argument('--epochs', default=500, type=int) # 训练轮数
parser.add_argument('--layers', default=3, type=int) # LSTM层数
parser.add_argument('--input_size', default=9, type=int) # 输入特征的维度
parser.add_argument('--hidden_size', default=64, type=int) # 隐藏层的维度64
parser.add_argument('--lr', default=0.0001, type=float) # learning rate 学习率
parser.add_argument('--sequence_length', default=7, type=int) # sequence的长度,默认是用前七天的数据来预测下一天的收盘价
parser.add_argument('--batch_size', default=64, type=int) # 批大小
parser.add_argument('--useGPU', default=False, type=bool) # 是否使用GPU
parser.add_argument('--batch_first', default=True, type=bool) # 是否将batch_size放在第一维
parser.add_argument('--dropout', default=0.001, type=float)
parser.add_argument('--save_file', default='model/stock.pkl') # 模型保存位置
parser.add_argument('--train_size', default=0.85, type=float) # 训练集的大小
parser.add_argument('--val_size', default=0.05, type=float) # 验证集的大小
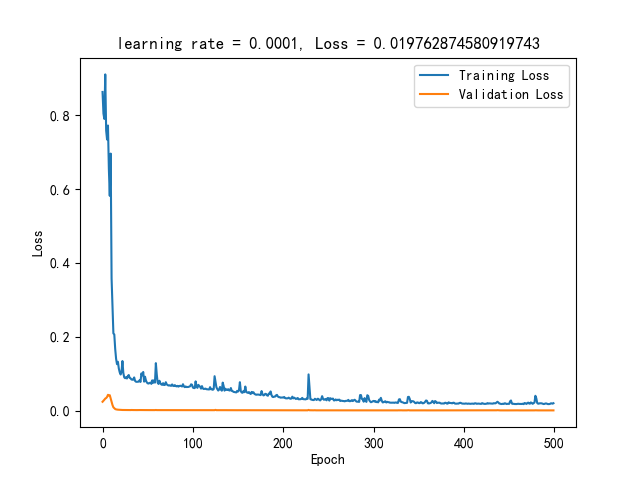
parser.add_argument('--test_size', default=0.1, type=float) # 测试集的大小经过500轮训练,得到训练和验证损失曲线。
在测试中,我们得到了LSTM模型对A股走势的预测结果。以下以图表的形式展示模型在测试集上的部分预测结果与实际值的对比情况,其中横坐标表示时间(以交易日为单位),纵坐标表示股票价格涨跌的预测值与实际值。
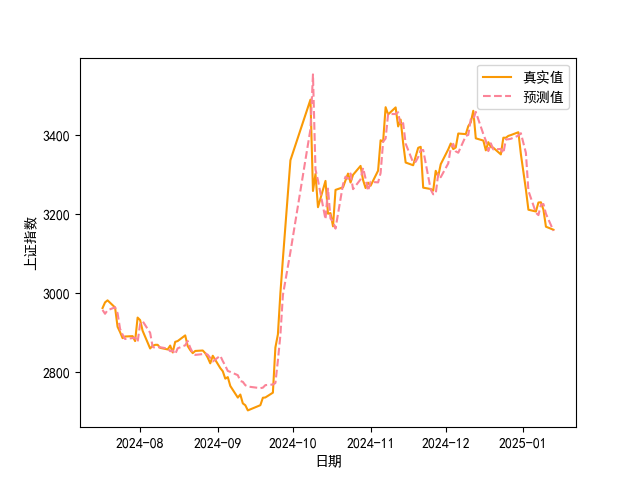
从图中可以看出,在大部分时间段内,模型能够较为准确地预测股票价格的涨跌。例如,在某些时间点,模型预测的上涨或下跌趋势与实际情况相符。然而,也存在一些预测不准确的情况,模型预测的涨跌与实际走势出现偏差。这可能是由于股票市场的复杂性,受到多种因素的综合影响,即使考虑了历史价格数据和股吧情感分析,仍难以完全准确地捕捉到所有的变化因素。
六、结论与展望
6.1 研究结论总结
本研究通过结合LSTM与股吧情感分析,构建了A股走势预测模型。实验结果表明,该模型在一定程度上能够有效预测股票价格的涨跌。通过对股吧文本数据进行情感分析,提取的投资者情感特征为模型提供了有价值的信息,有助于提高预测的准确性。
6.2 研究的局限性
数据方面:本实验使用的数据在时间跨度和样本数量上存在一定的局限性。股票市场受到众多复杂因素的影响,历史数据的时间跨度不够长可能导致模型无法充分学习到各种市场状态下的规律。此外,股吧文本数据的抓取可能存在不全面的情况,部分重要信息可能被遗漏,从而影响情感分析的准确性和模型的预测效果。
模型方面:虽然LSTM模型在处理时间序列数据方面具有优势,但股票市场的复杂性使得任何单一模型都难以完全准确地捕捉所有影响因素。本研究中LSTM模型的结构和参数设置可能并非最优,仍有进一步优化的空间。此外,模型假设投资者的情感能够直接反映在股票价格走势中,但实际情况可能更为复杂,投资者情感与股票价格之间的关系可能受到多种因素的干扰。
情感分析方面:snownlp库的情感分析方法虽然简单易用,但对于金融领域文本的情感分析可能存在一定的局限性。金融文本具有专业性和复杂性,其中的一些词汇和表达方式可能具有特定的含义,普通的情感分析工具可能无法准确理解其情感倾向。此外,情感分析结果可能受到文本的上下文、语境等因素的影响,目前的方法可能无法充分考虑这些因素。
6.3 未来研究方向
数据拓展:收集更长时间跨度、更多样本的股票历史交易数据和股吧文本数据,以提高模型的泛化能力和稳定性。同时,可以考虑拓展数据来源,如收集更多金融媒体的评论、分析师报告等,以获取更全面的市场信息。
模型改进:尝试改进LSTM模型的结构,如引入注意力机制等,以更好地捕捉数据中的重要信息和长期依赖关系。此外,可以结合其他机器学习或深度学习算法,构建集成模型,提高预测的准确性。
情感分析优化:针对金融领域文本的特点,改进情感分析方法。可以利用深度学习模型,如基于Transformer的模型,进行情感分析,以提高分析的准确性和鲁棒性。同时,可以考虑结合知识图谱等技术,更好地理解金融文本中的语义和情感。
多因素融合:进一步研究股票市场的其他影响因素,如宏观经济指标、行业动态、公司财务状况等,并将这些因素与投资者情感和历史价格数据进行更深入的融合,以构建更全面、准确的股票走势预测模型。
参考文献
[1] Zhang Y S, Yang S T. Prediction on the Highest Price of the Stock Based on PSO-LSTM Neural Network[C]// Proceedings of the 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE). 2019: 1565-1569.
[2] Xing FZ, Cambria E, Welsch RE (2018) Natural language based financial forecasting: a survey. Artif Intell Rev 50(1):49–73
[3] Xu Yuemei, Wang Zihou, Wu Zixin. Predicting Stock Trends with CNN-BiLSTM Based Multi-Feature Integration Model[J]. Data Analysis and Knowledge Discovery, 2021, 5(7): 126-138
Comments NOTHING