1 深度学习基础
交叉熵损失(Cross-Entropy Loss)是衡量两个概率分布差异的函数,最早由信息论领域的 Claude Shannon 提出。交叉熵损失广泛应用于机器学习和深度学习模型中,尤其在分类任务中用于优化模型性能。
$$
L_{CE}=-\sum_{i=1}^ny_i\log(\hat{y_i})
$$
其中, $y_i$是真实标签, $\hat{y_i}$是模型预测的概率分布,$n$是分类类别的数量。
交叉熵损失度量了模型输出的概率分布$\hat{y_i}$和真实标签分布$y_i$之间的差异。交叉熵越小,表示两个分布越接近,即预测的类别概率分布越接近真实标签。交叉熵损失的目标是最小化该值,使得模型输出的预测概率与真实标签的分布尽可能接近。
梯度下降法
$$
\theta^i=\theta^{i-1}-\eta\nabla C(\theta^{i-1})
$$

反向传播算法:先前馈计算每一层的状态和激活值,直到最后一层;反向传播计算每一层的误差;计算每一层参数的偏导数,并更新参数。
$$
\delta^{L-1}=\sigma^{\prime}(Z^{L-1})\cdot(W^L)^\top\delta^L
$$
其中,$\delta^{L-1}$是我们需要计算的目标,即 第 L-1 层的误差项。$\delta^L$是 第 L 层的误差项,是计算的起点。$\sigma^{\prime}(Z^{L-1})$是激活函数 σ 在第 L-1 层神经元的加权输入$Z^{L-1}$处的导数值。

梯度消失问题:在神经网络中误差反向传播的过程中,其中需要用到激活函数$\sigma(Z^{L-1})$的导数误差从输出层反向传播时每层都要乘激活函数导数。这样当激活函数导数值小于 1 时 ,误差经过每一层传递都会不断衰减,当网络很深时甚至消失。
解决梯度梯度消失问题方法:
- 选择合适的激活函数
- 用复杂的门结构代替激活函数
- 残差结构
解决过拟合问题方法:
- Dropout
- 损失函数加入适当的正则项
CNN有三个结构上的特性:卷积(局部连接、权重共享)、池化(空间或时间上的次采样)。
DNN、CNN 输入、输出定长;处理输入、输出变长问题效率不高。 而自然语言处理中的语句通常其长度不固定。解决方法:RNN(循环神经网络)。
RNN核心思想: 将处理问题在时序上分解为一系列相同的“单元”,单元的神经网络可以在时序上展开,且能将上一时刻的结果传递给下一时刻,整个网络按时 间轴展开。即可变长。
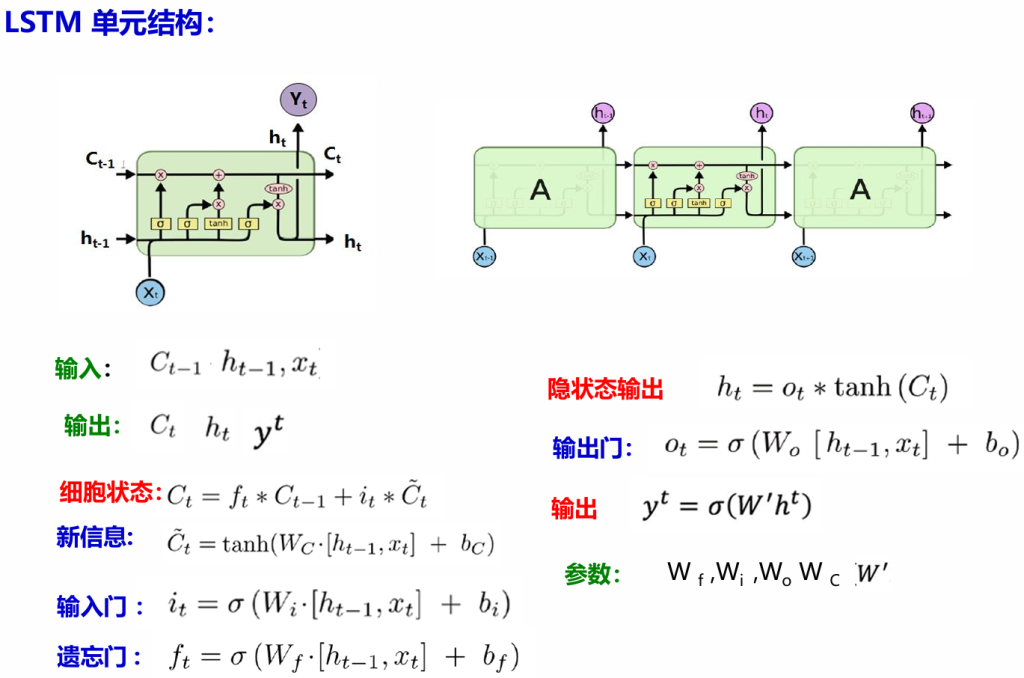
LSTM(长短时记忆神经网络):LSTM单元不仅接受$x_t$和$h_{t-1}$,还需建立一个机制(维持一个细胞状态$C_t$) 能
保留前面远处结点信息在长距离传播中不会被丢失。LSTM 通过设计“门”结构实现保留信息和选择信息功能。
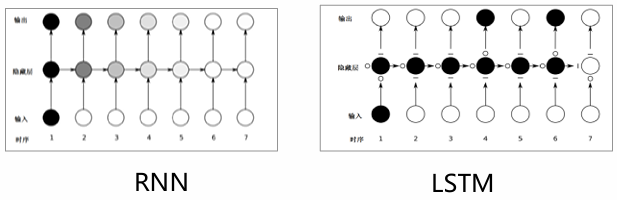
遗忘门、输入门、输出门
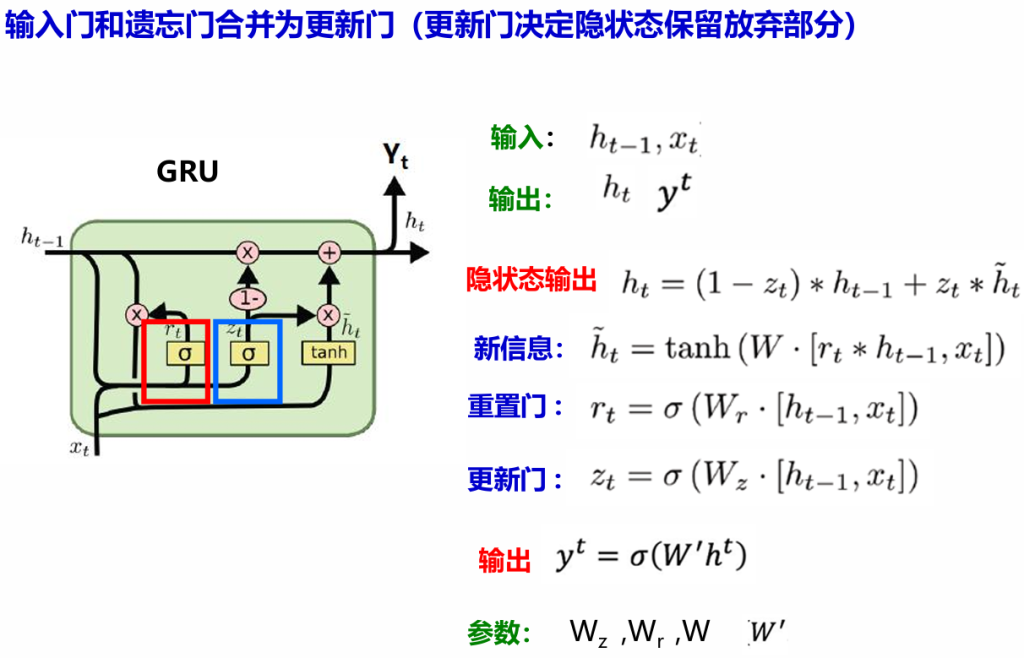
GRU:简化LSTM,输入门和遗忘门合并为更新门(更新门决定隐状态保留放弃部分)。
2 语言模型与词向量
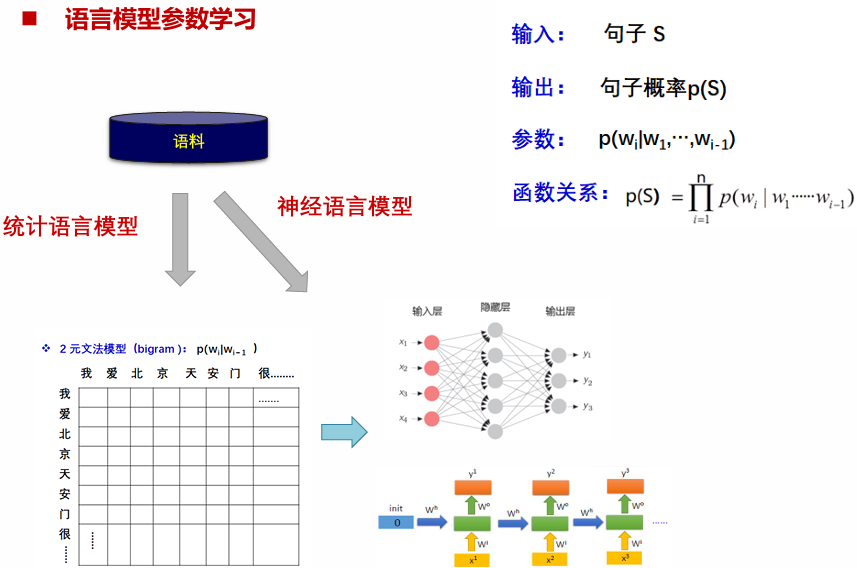
语言模型基本概念:用句子$S=w_1,w_2,…,w_n$ 的概率 $p(S)$ 刻画句子的合理性(统计自然语言处理的基础模型)

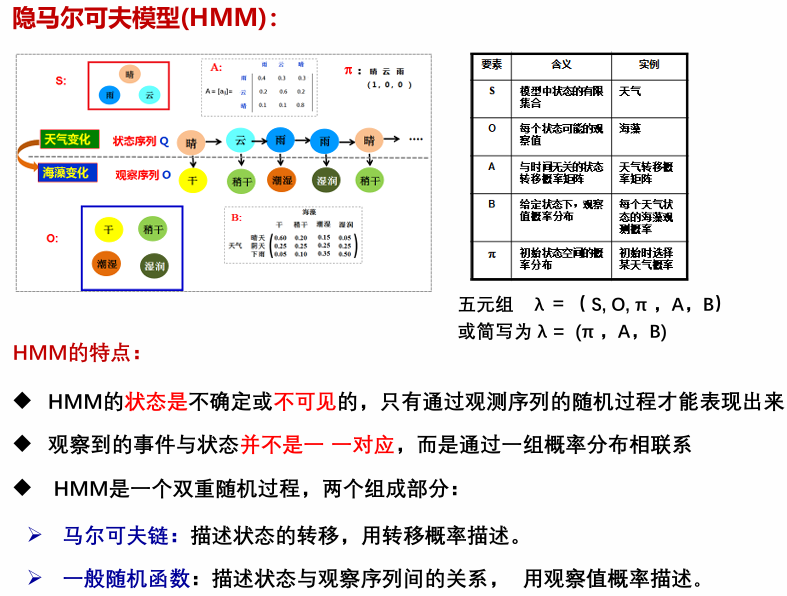
隐马尔科夫模型:该模型是一个双重随机过程,我们无法观测具体的状态序列,只知道状态转移的概率,即模型的状态转换过程是不可观察的(隐蔽的) 而可观察事件的随机过程是隐蔽状态转换过程的随机函数。

词向量
词的表示:自然语言问题要用计算机处理时,第一步要找一种方法把这些符号数字化,成为计 算机方便处理的形式化表示。
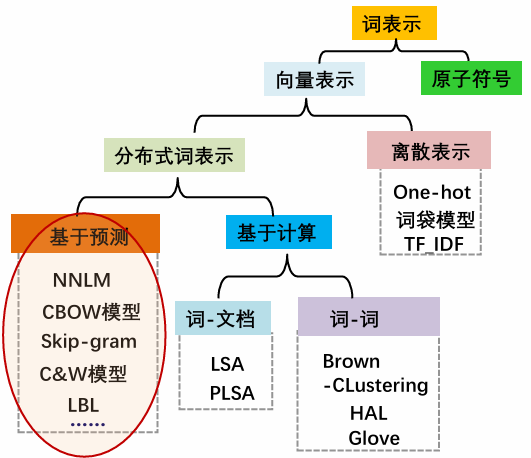
神经网络词向量:不计算词之间的共现频度,直接用“基于词的上下文词来预测当前词”或“基于当前词预测上下文词”的方法构造构造低维稠密向量作为词的分布式表示。
神经语言模型:用神经网络方法学习语言模型参数(NLP 里程碑成果)
词的 One-Hot 表示:用一个非常长的、只包含一个1和大量0的向量来表示一个词。每个词的 one-hot 向量长度等于词汇表的大小。向量中,只有该词对应索引的位置是1,其他位置全是0。
Look-up 表(查找表,通常指 Embedding Layer/嵌入层):一个可以学习的“密码本”或“花名册”,它将高维稀疏的 one-hot 向量“翻译”成低维稠密且有意义的向量(即词向量)。
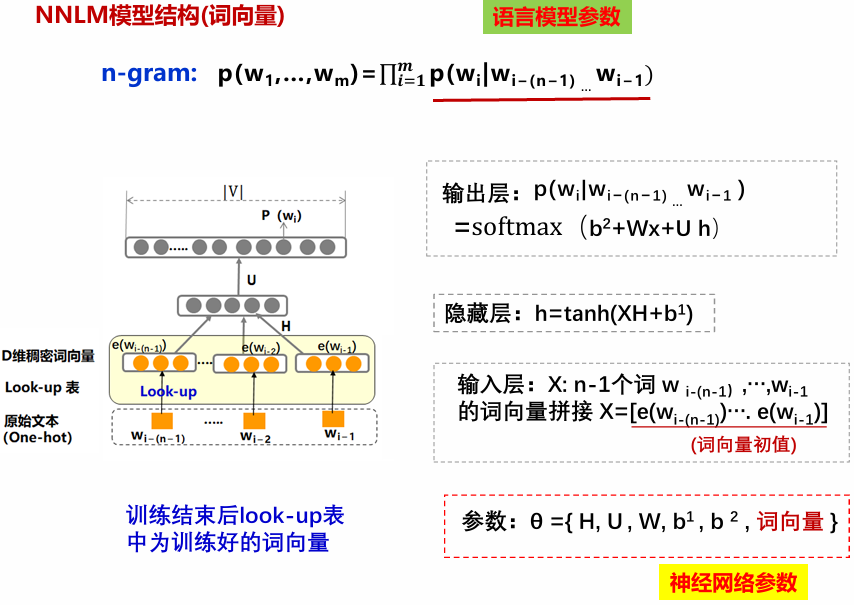
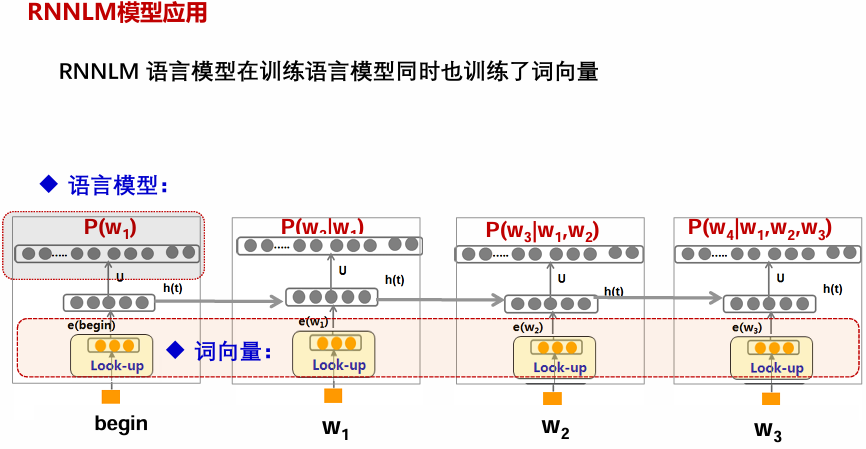
RNNLM 模型可以保留每个词的全部历史信息,不需简化为n-gram。引入词向量作为输入后不需要数据平滑。
Mikolov等人在2013年,同时提出CBOW(Continuous Bag-of-Words)和Skip-gram模型。主要针对NNLM训练复杂度过高的问题进行改进,简化模型,保留核心部分,以更高效的方法获取词向量。
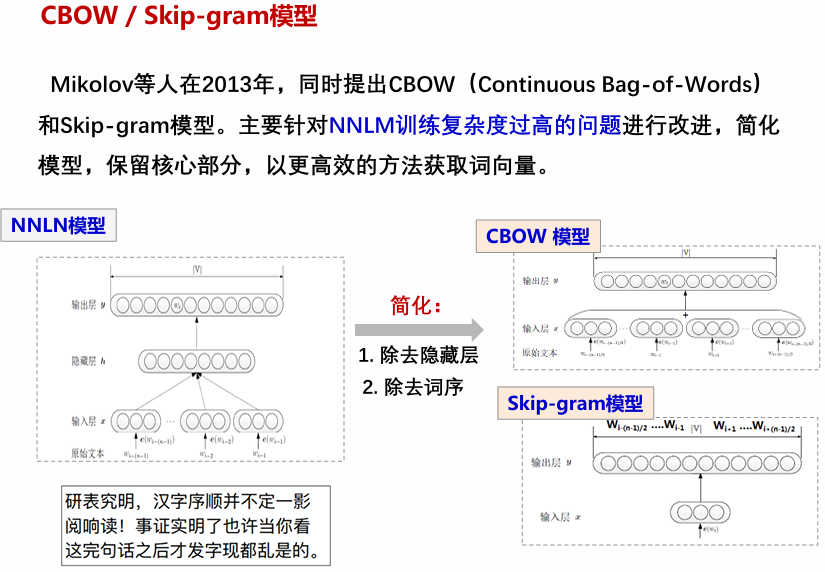
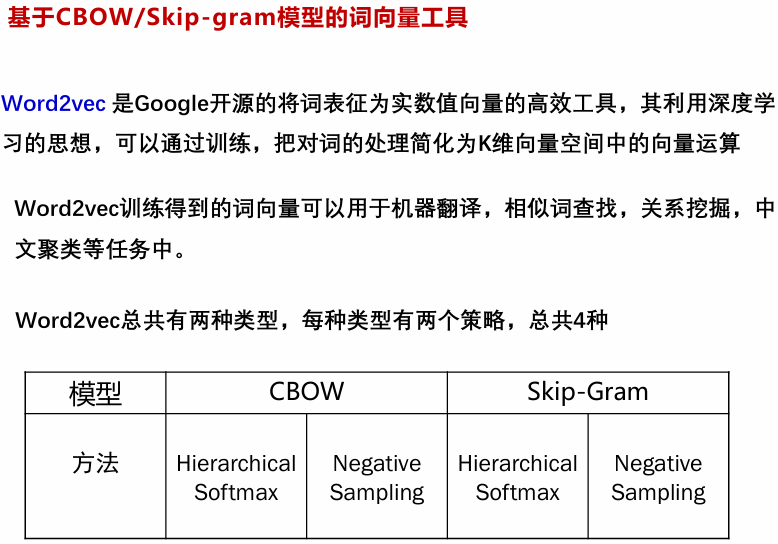
Word2Vec主要包含两种模型:Skip-Gram(跳字模型)和CBOW(Continuous Bag of Words,连续词袋模型)。
Skip-Gram与CBOW模型的主要差异在于训练方式:Skip-Gram 通过中心词预测上下文词汇,类似于“由点及面”的扩展;而CBOW则是利用上下文词汇预测中心词,类似于“由面定点”的填充。前者注重于从局部到整体的推理,后者则强调整体对局部的反映。
模型真正的目标不是完美地完成这个预测任务,而是在完成这个任务的过程中,让模型学会的权重参数能够很好地捕捉词语的语义和语法信息。模型训练好之后,词向量是输入层到隐藏层的权重矩阵。
3 预训练语言模型
动态词向量(ELMo)的核心理念:一个词的向量表示是基于其完整的上下文动态生成的。同一个词在不同的句子中会有不同的向量。
- Word2Vec是“一个词,一个向量”;ELMo是“一个实例(occurrence)一个向量”。
- 解决一词多义: 这是ELMo最大的贡献。它能为“我今天吃了一个苹果”和“我买了一部苹果手机”中的两个“苹果”生成不同的向量,准确捕捉其语义差异。
注意力机制
注意力机制是一种模拟人类认知注意力的计算技术,用于处理序列数据(如文本)。其核心思想是:对于给定的查询(Query),模型通过计算查询与一系列键(Key)的相似度(如点积),生成注意力权重(经softmax归一化),然后使用这些权重对对应的值(Value)进行加权求和,从而突出输入中相关信息的重要性。简单来说,它允许模型动态地聚焦于输入的不同部分,而不是平等对待所有元素。
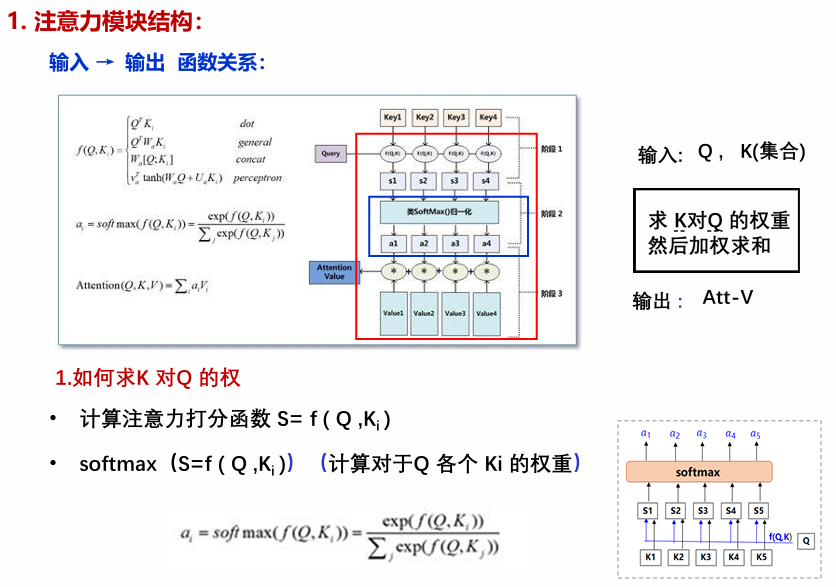
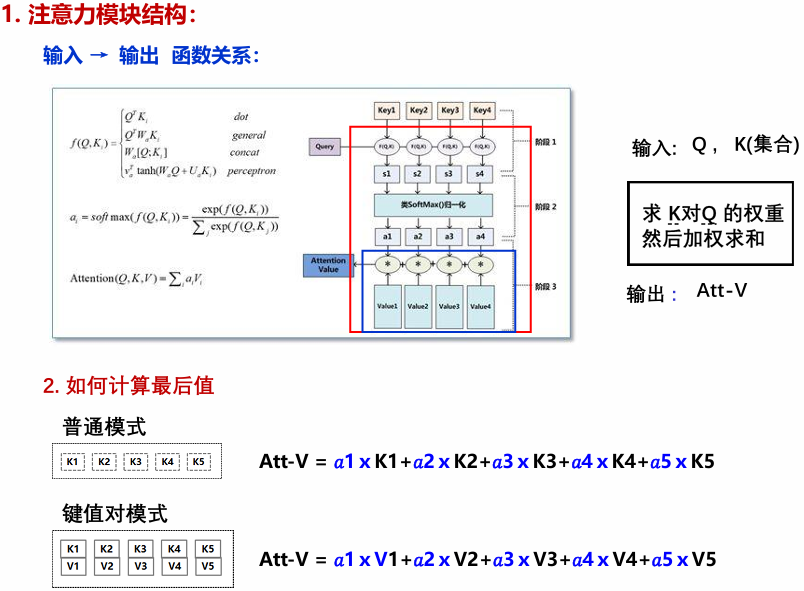
自注意力(Self-Attention):是注意力机制的特殊形式,其中查询、键和值均来自同一输入序列。这使得每个位置可以直接关注序列中的所有其他位置,从而捕获序列内部的长期依赖关系。例如,在句子中,一个词可以通过自注意力直接与句首或句尾的词交互,无需像RNN那样逐步传递信息。这显著提高了模型对全局上下文的理解能力,避免了梯度消失问题。
多头注意力(Multi-Head Attention):通过使用多个独立的注意力头(每个头学习不同的查询、键、值投影),模型能够并行地从多个子空间(如语法、语义、语用等角度)捕获多样化的上下文信息。多个头的输出被拼接和线性变换,集成不同视角的注意力模式。这种设计增强了模型的表示能力,使其能更鲁棒地处理复杂语言结构(如歧义或长距离依赖),防止过拟合到单一模式。多头就是做多次同样的事情(参数不共享),然后把结果拼接。
- 长距离依赖建模困难
- 上下文理解
Transformer
Transformer的原始结构。它包含两个主要部分:
- 编码器:双向编码,擅长理解和表征输入。它是双向的,在计算每个词的表示时,可以同时看到其左右上下文的所有词。
- 解码器:单向自回归,擅长生成序列。它是单向的,在计算当前词的表示时,只能看到它左边(之前)的词,这是为了在生成时不会“偷看”到未来的答案。
GPT 模型结构:GPT 采⽤了 Transformer 的 Decoder 部分,并且每个⼦层只有⼀个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和⼀个 Feed Forward,模型共叠加使用了 12 层的 Decoder普通transformer解码器层的编码器-解码器注意力子层。
Bert 模型结构:使用堆叠的双向Transformer Encoder,在所有层中共同依赖于左右上下文基础版是12个Encoder (12层 );高级版24个Encoder (24层 )。
BART 模型结构:BART采用标准Transformer结构
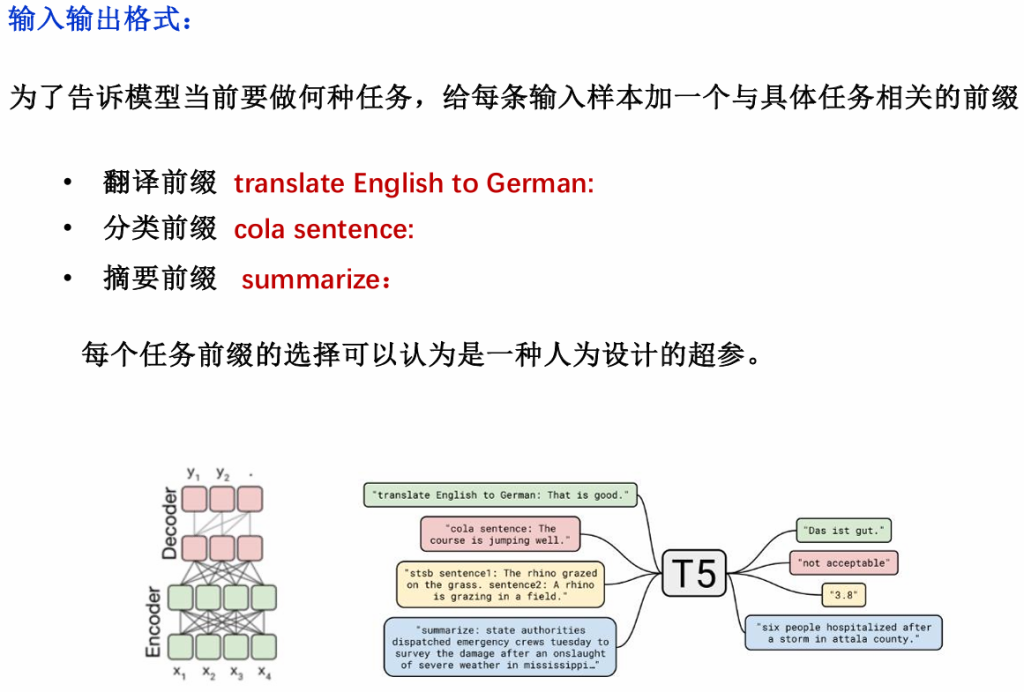
T5:给整个NLP 预训练模型领域提供了一个通用框架,把所有NLP任务都转化成一种形式(Text-to-Text),通过这样的方式可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
4 大语言模型
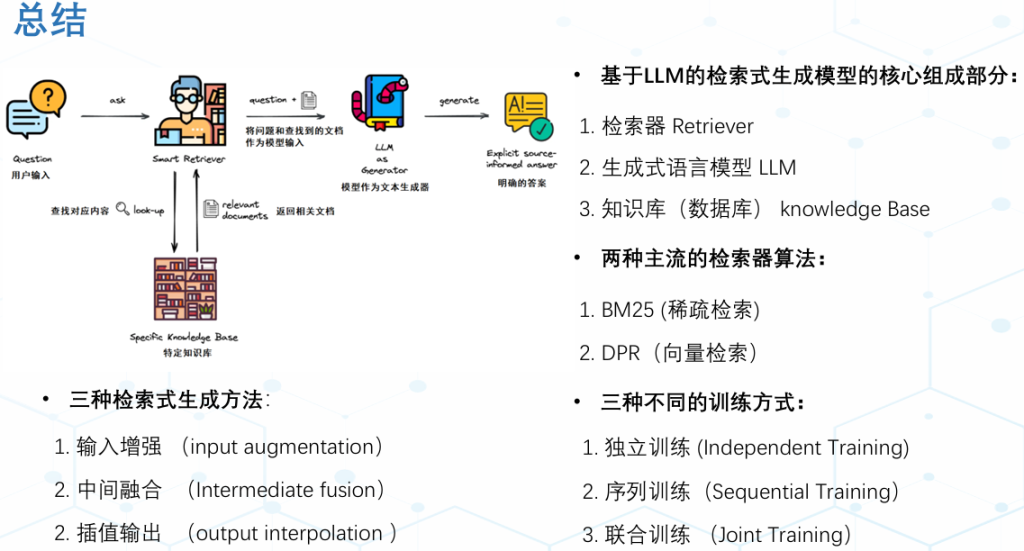
RAG
基于LLM的检索式生成模型,包括检索器 Retriever、生成式语言模型LLM、知识库 knowledge Base


上下文学习(In-context Learning)是一种学习范式,是现代自然语言处理领域中一种重要的学习方法,尤其在使用大规模,尤其在使用大规模预训练模型时,它允许模型在给定的上下文中进行学习和推理,而无需真正更新模型参数。

Fine-tuning
微调(Fine-tuning):预训练好的模型然后在特定任务的数据上进行进一步的训练。这个过程通常涉及对模型的权重进行微小的调整,以使其更好地适应特定的任务,得到最终能力各异的模型。
大模型微调的方法:
- 全量微调通过在预训练的大型模型基础上调整所有层和参数,使其适应特定任务。这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,但可能需要更多的计算资源。
- 参数高效微调(PEFT)技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。PEFT包括LORA、QLoRA、Adapter Tuning、Prefix Tuning、Prompt Tuning、P-Tuning及P-Tuning v2等。
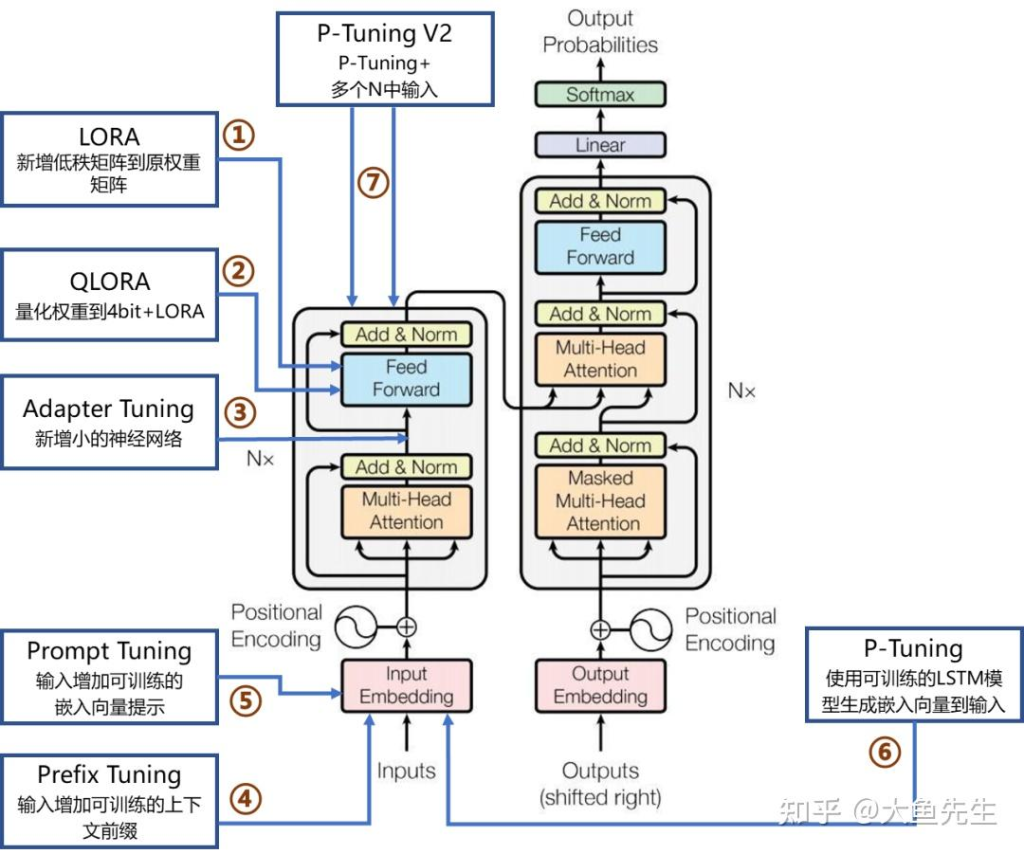
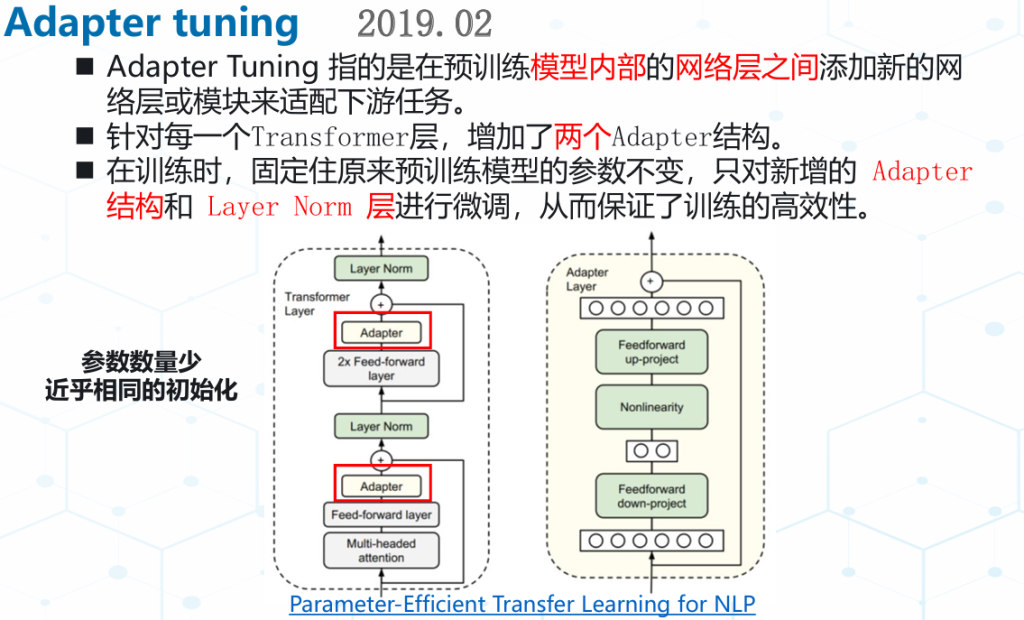
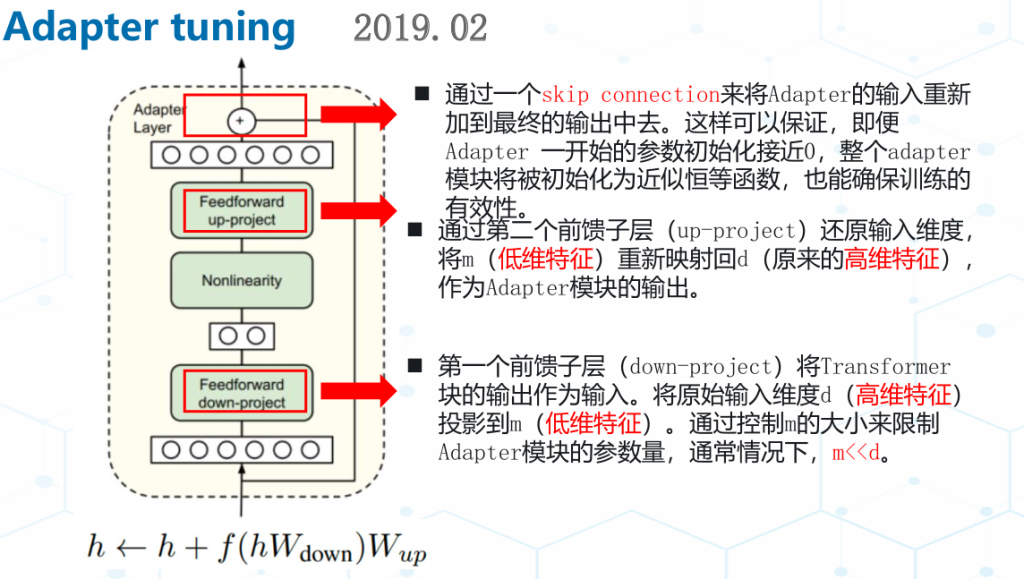
Adapter模块的添加导致模型整体参数量增加,降低了模型推理时的性能。 与全量微调相比Adapter在训练时快60%,但是在推理时慢4%-6%。
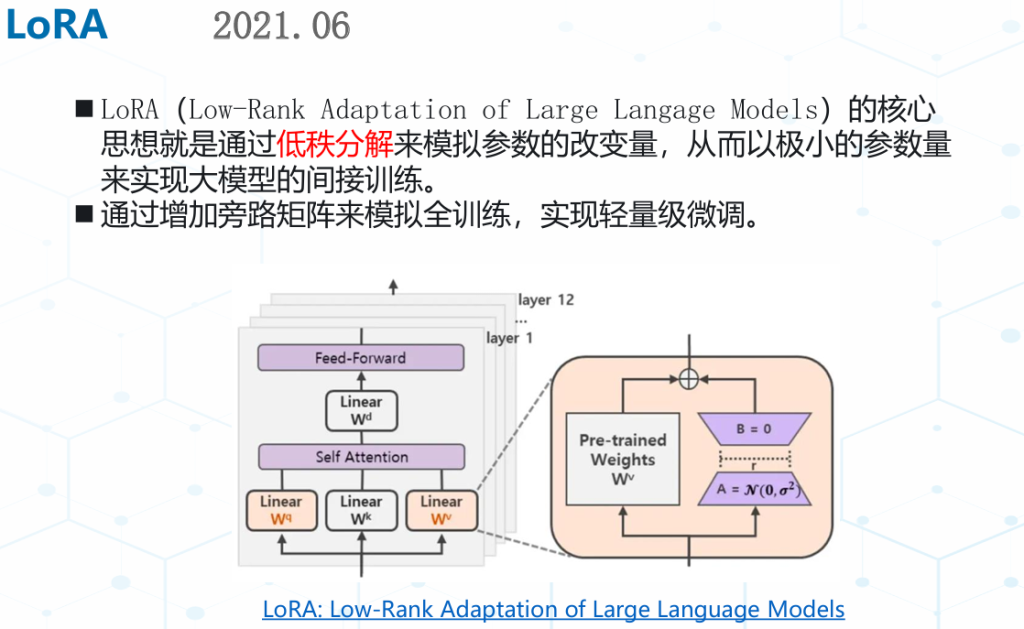
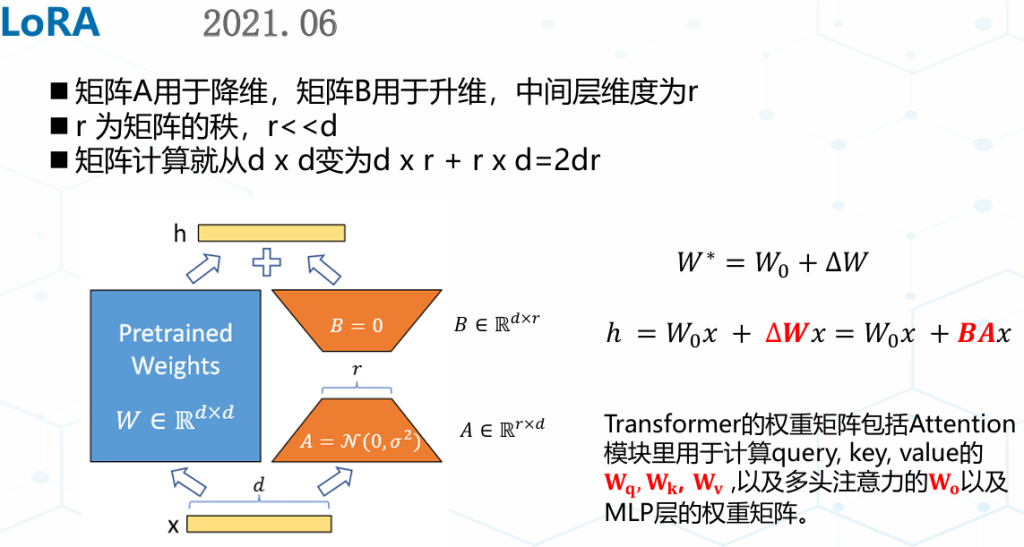
Lora没有推理延迟,但需要预先指定每个增量矩阵的秩r ,忽略了在微调预训练模型时,权重矩阵的重要性在不同模块和层之间存在显著差异。LoRA 块大小固定,训练后无法修改,如果需要调整矩阵的秩,只能从头开始训练。优化并找到不同秩下面的最优模型是一个繁琐的过程。
Comments NOTHING