1 多模态数据融合
模态表示是将不同感官或交互方式的数据(如文本、图像、声音等)转换为计算机可理解和处理的形式,以便进行后续的计算、分析和融合。多模态融合能够充分利用不同模态之间的互补性,它将抽取自不同模态的信息整合成一个稳定的多模态表征。从数据处理的层次角度将多模态融合分为数据级融合、特征级融合和目标级融合。
- (a)数据级融合,也称为像素级融合或原始数据融合,是在最底层的数据级别上进行融合。这种融合方式通常发生在数据预处理阶段,即将来自不同模态的原始数据直接合并或叠加在一起,形成一个新的数据集。
- (b)特征级融合是在特征提取之后、决策之前进行的融合。不同模态的数据首先被分别处理,提取出各自的特征表示,然后将这些特征表示在某一特征层上进行融合。
- (c)目标级融合,也称为决策级融合或后期融合,是在各个单模态模型分别做出决策之后进行的融合。每个模态的模型首先独立地处理数据并给出自己的预测结果(如分类标签、回归值等),然后将这些预测结果进行整合以得到最终的决策结果。
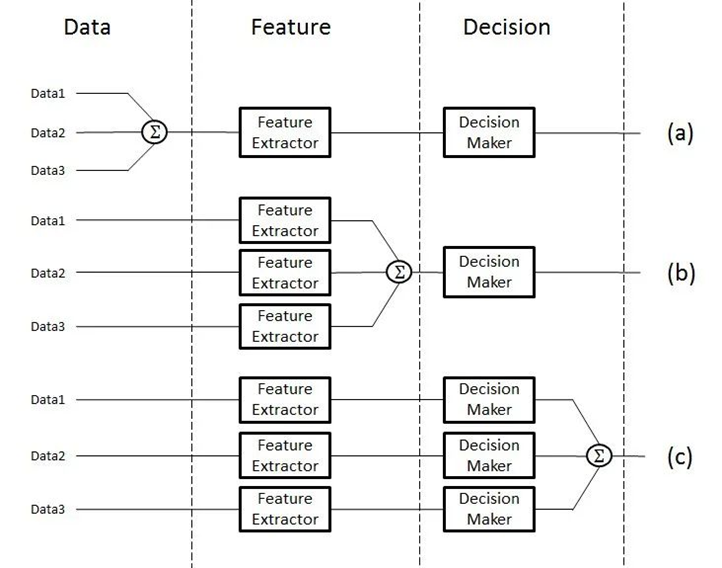
多模态人工智能(Multimodal Artificial Intelligence)涉及各种类型的数据(如图像、文本或从不同传感器收集的数据)、特征工程(如提取、组合/融合)和决策(如多数票)。随着架构越来越复杂,多模态神经网络可以将特征提取、特征融合和决策过程整合到一个模型中。这些过程之间的界限越来越模糊。[1]提出了一种新的细粒度分类法,将最先进的(SOTA)模型分为五类:编码器-解码器方法、注意机制方法、图神经网络方法(GNN)、生成神经网络方法(GenNN)和其他基于约束的方法。
2 华为智驾系统ADS
华为ADS采用"激光雷达(Lidar)+毫米波雷达(Radar)+视觉摄像头(Camera)+超声波传感器(IMU)"的多模态融合方案。决策层,基于深度学习的混合决策模型,融合规则驱动与数据驱动方法。
ADS3.0架构仅车端,采用端到端大模型,其中感知部分使用GOD(通用障碍物识别)大感知网络,而决策规划部分通过PDP(预测-决策-规划)网络来实现,同时添加本能安全网络提升表现。

ADS4架构增加云端的世界引擎,难例扩散生成模型,安全强化学习。车端为全模态感知、MoE混合专家模型。

Tokenizer 是一种将原始数据(如文字、图像或视频)转化为模型可以处理的基础单位(即 Token)的工具。Token是否能够代表原始数据的含义,直接影响模型的输入质量和后续处理效率。
- 文字由于其离散性,主要以基于词表的方法构建Tokenizer,因此变体较少。
- 图像或者视频没有类似文字的“离散语义单位”,需要通过人工设计或模型提取来划分为 token 表示。主要代表模型:VIT(Vision Transformer)。
3 华为鸿蒙座舱

参考
一文彻底搞懂多模态:模态表示、多模态融合、跨模态对齐-CSDN博客
华为乾崑智能汽车解决方案
华为乾崑ADS1.0到4.0全面梳理,D5激光雷达2025 年将发布 - 知乎
多模态Tokenizer总结 - 知乎
[1] Fei Zhao, Chengcui Zhang, and Baocheng Geng. 2024. Deep Multimodal Data Fusion. ACM Comput. Surv. 56, 9, Article 216 (September 2024), 36 pages. https://doi.org/10.1145/3649447
Comments NOTHING