1. 前言
在大语言模型进行微调的流程中,一般在监督微调(Supervised Fine-Tuning,SFT)阶段之后,进一步通过强化学习对模型进行优化可以显著提升其性能。而群体相对策略优化(Group Relative Policy Optimization,GRPO),就是使用在该阶段,替换传统的近端策略优化(Proximal Policy Optimization,PPO)算法。
PPO是OpenAI在2017提出的一种强化学习算法,适用于对 LLM 进行微调。PPO 的目标是通过最大化以下替代目标函数来优化策略模型。
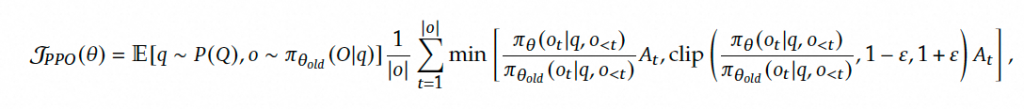
GRPO不再需要像PPO那样加入额外的价值函数近似,而是直接使用多个采样输出的平均奖励作为Baseline,显著减少了训练资源的使用。
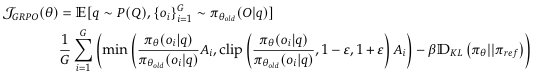
2. GRPO与PPO的区别
PPO基于优势函数估计和 KL 散度约束的策略优化。
1. 利用价值网络(Critic网络)估计状态价值,使用广义优势函数(GAE )估计优势。
- 估计优势函数GAE:核心思想是通过时间差分(TD)误差的加权和,估计优势函数。
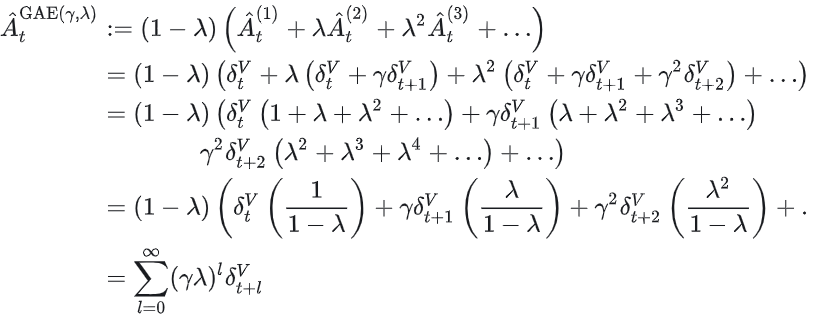
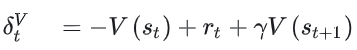
- (折扣因子): 越小,智能体越关注即时奖励(短视); 越大,智能体越考虑长期收益(但可能导致训练不稳定)。
- (GAE权衡参数):,仅使用单步TD误差(低方差,高偏差),等价于原始策略梯度;:使用无限步MC误差(高方差,低偏差),接近蒙特卡洛估计;
2. 构建带 KL 惩罚的目标函数进行策略更新
- KL散度定义:它衡量的是同一个随机变量X的两个概率分布P和Q之间的差异。注意,它衡量的是用分布Q来近似分布P时所损失的信息量。从信息论的角度解释,KL散度 = 交叉熵 - 信息熵。
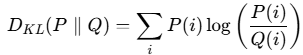
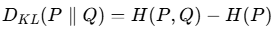
- KL惩罚项:策略模型和参考模型之间的KL散度来正则化,有四种。

- PPO使用K1作为惩罚项加入奖励中;GRPO使用K3作为惩罚项直接加到损失中。GRPO目标是省去Critic网络,直接用Reward的统计量(均值和标准差)来替代优势函数,简化计算。
3. 模型结构
1. GRPO模型结构:Policy Model->Reference Model+Reward Model->Group Computation
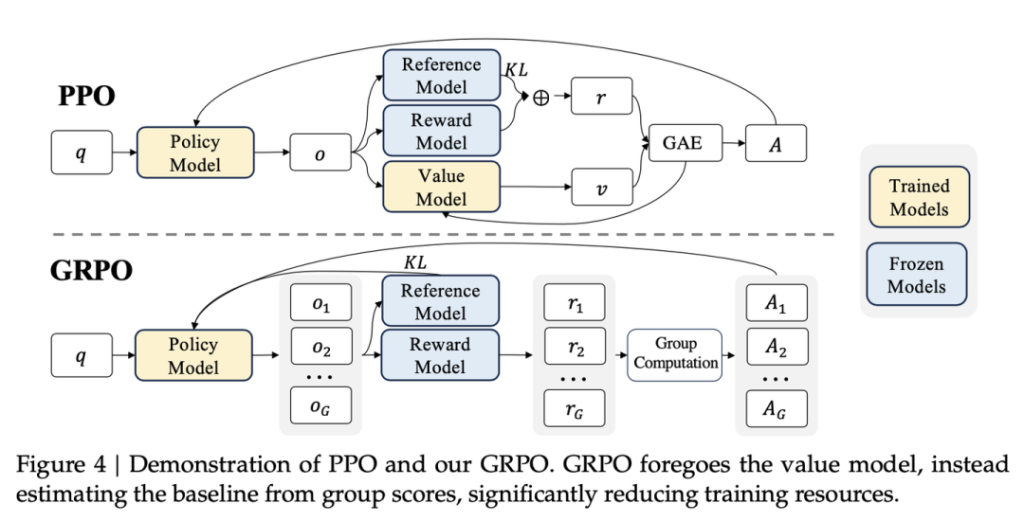
2. Policy Loss:
- PPO:剪裁后的替代目标函数
在奖励中加入 KL 惩罚项 - GRPO:剪裁后的替代目标函数+策略模型和参考模型之间的 KL 散度来正则化
优势函数估计
3. Reference Model:基准模型,用于防止训练过程中模型过度偏移原始分布,确保稳定性。
4. Reward Model:
- 最常见的Reward Model有两种:(i) Outcome Reward Model (ORM):这种模型关注的是最终结果的质量,即模型生成的输出是否满足目标要求。ORM通过对生成的最终答案进行评分,来评估模型的表现。(ii) Process Reward Model (PRM):与ORM不同,PRM不仅仅关注最终答案,还对模型的推理过程进行评分。PRM在生成答案的过程中逐步激励或惩罚模型,引导模型朝着更可解释、更稳定的推理路径发展。
- 论文arxiv.org区分了三种奖励生成范式(Reward Generation Paradigms)主要方法:标量、半标量和生成式。(a) 标量方法为给定的查询和响应分配标量值。(标量值是一个单一的数值,通常用来表示某种评价或奖励。)(b) 半标量方法生成文本判断,称为“批评”,以及标量奖励值。(批评是一种更详细的反馈,以文本形式呈现。)(c) 生成方法只生成批评作为文本奖励,可以从中提取奖励值。评分模式 (Scoring Patterns) 主要有两种:(i) 点式 (Pointwise):这种方法独立地为每一个给定的回复分配一个分数。它可以接受单个或多个回复作为输入,并为每个回复都给出一个评估。(ii) 成对 (Pairwise):这种方法主要考虑两个回复之间的相对偏好。模型通常会判断在给定的两个回复中,哪一个更好。虽然这种方法可以扩展到处理多个回复,但通常需要额外的技术。
- 3种奖励生成范式+2种评分模式组成5种Reward Model(a) 标量 (Scalar) + (i) 点式 (Pointwise) - 代表方法:Bradley-Terry(a) 标量 (Scalar) + (ii) 成对 (Pairwise) - 代表方法:PairRM(b) 半标量 (Semi-Scalar) + (i) 点式 (Pointwise) - 代表方法:CLoud(b)/(c) 生成式 (Generative) + (ii) 成对 (Pairwise) - 代表方法:LLM-as-a-Judge / TokenProb(c) 生成式 (Generative) + (i) 点式 (Pointwise) - 代表方法:GRM
DeepSeek R1 Reward Model由准确性奖励(Accuracy rewards)和格式奖励(Format rewards)组成。
- Accuracy rewards:评估模型的回复是否准确。基于规则的。
- Format rewards:强制模型将思考过程放在'<think>'和'</think>'之间。
DeepSeek 生成式奖励模型(GRM)将自原则批评调整(SPCT)用于逐点GRMs,SPCT 由两个阶段组成:拒绝性微调(RFT),作为冷启动,以及基于规则的在线RL,通过推进生成的原则实现强化通用奖励的生成。SPCT也在GRM中培养这些行为,以实现推理时间缩放。
- 拒绝性微调:核心理念是使 GRM 能够以正确的格式并针对各种输入类型生成原则(Principles)和评论(Critiques)。(通过在微调过程中主动过滤掉低质量或无信息量的训练数据来提高GRM的质量和可靠性。)点式 GRM,对于每个查询和相应的响应,都要进行 NRFT 次采样。以生成可能的轨迹 ?{Principles, Critiques, Raw_Reward}剔除预测奖励(Predicted Reward)与真实奖励(Ground Truth)不一致的轨迹(不正确),以及查询和回复中所有 NRFT 轨迹都正确的轨迹(太容易)。
- 基于规则的在线RL:采用GRPO算法框架,使用基于规则的ORM
- GRM根据查询x和多个回复y_i,实时生成对应的奖励Principles和Critiques。
- Predicted Reward,与Ground Truth(基于规则生成)进行比对。
- 只有一个回复(n=1),模型Predicted Reward Sj等于基于规则给的Ground Truth rj,奖励为1。多个回复(n>1),模型Predicted Reward Sj’最大,刚好对应的Ground Truth也是最大的,奖励为1。其他情况,奖励为-1。
参考文献
详解DeepSeek-R1核心强化学习算法:GRPO
GAE 广义优势估计
PPO、GRPO等RL中的KL散度计算方法及实现
Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning[J]. arXiv preprint arXiv:2501.12948, 2025.
Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models[J]. arXiv preprint arXiv:2402.03300, 2024.
Comments NOTHING