发布于 2025-08-07
摘要
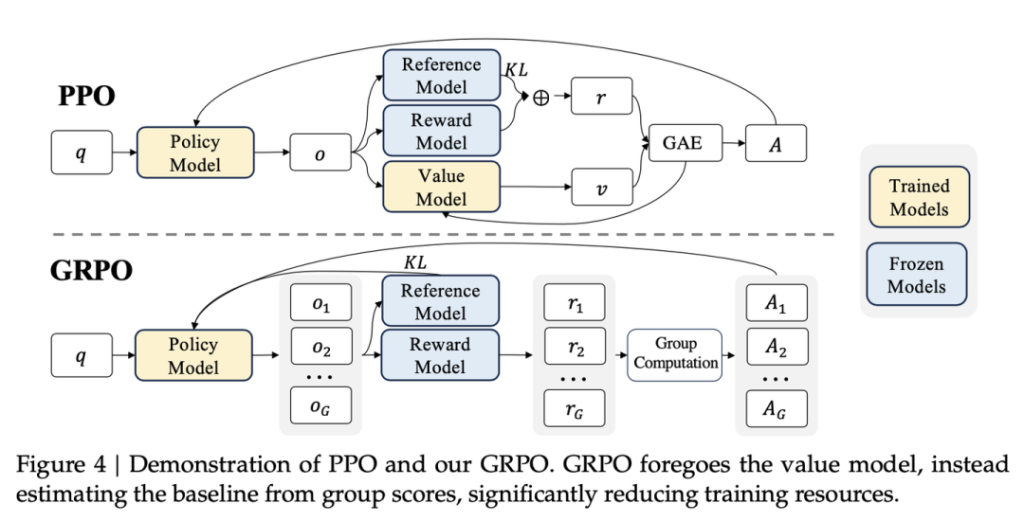
1. 前言 在大语言模型进行微调的流程中,一般在监督微调(Supervised Fine-Tuning,SFT)阶段之后,进一步通 …
1. 前言 在大语言模型进行微调的流程中,一般在监督微调(Supervised Fine-Tuning,SFT)阶段之后,进一步通 …