原文:https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
这篇文章由 Anthropic 工程团队于 2026 年 1 月发布,是一篇关于如何系统性地评估(Evaluations / Evals)AI 智能体(AI Agents)的实战指南。文章的核心观点是:“没有评估体系的团队在生产环境中无异于‘盲目飞行’(Flying blind),根本无法区分真正的性能退化(Regression)和系统的随机噪音”。
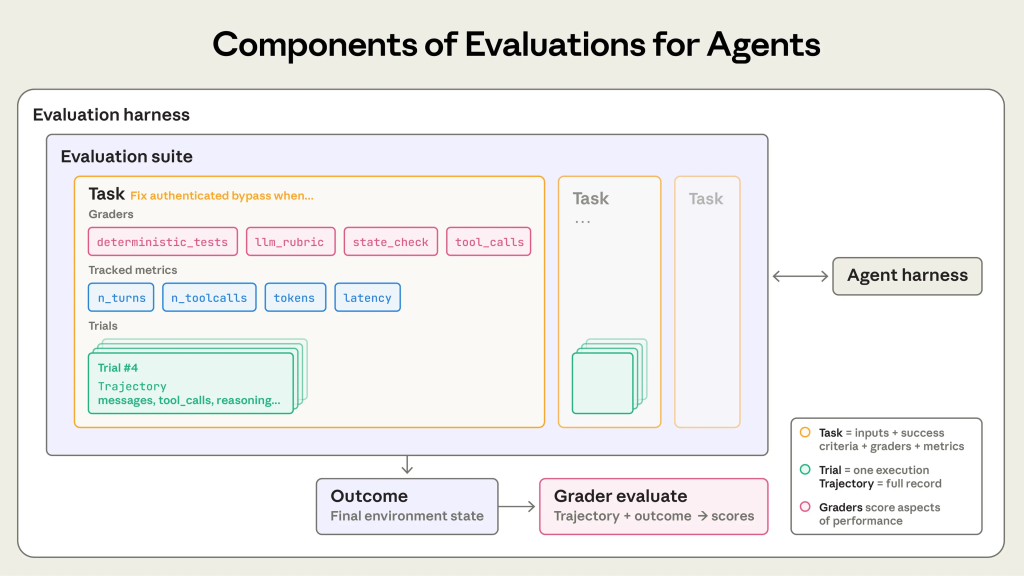
评估是 AI Agent 走向严肃软件工程的基础。以下是文章的核心要点总结:
1. 为什么 Agent 的评估比传统 LLM 更难?
- 从单轮转向多轮(Multi-turn):传统大模型的评估通常是“提示词-回复-打分”的单轮模式。而 Agent 涉及多步推理、工具调用(Tool use)、修改环境状态等复杂操作。
- 误差的传播与复合:在多步操作中,早期的一个小错误可能会像滚雪球一样在后续步骤中被放大并导致彻底偏离目标。
- 非确定性(Non-determinism):Agent 在相同任务下可能表现出不同的行为路径。更棘手的是,它们常常能找到出乎意料的“捷径”或“漏洞”来完成任务,导致死板的基准测试在误判它们“失败”时,用户反而觉得是“成功”的。
2. 推荐的三种评分器(Graders)组合
为了应对复杂性,Anthropic 建议结合使用以下三种评分机制:
- 基于代码的评分器(Code-based graders):如单元测试、正则匹配、静态分析或状态检查。
- 特点:速度快、成本低、客观且可复现。
- 缺点:过于死板,容易对 Agent 找出的有效但非标准的解决方案产生误判。
- 基于模型的评分器(Model-based / LLM-as-a-judge):让另一个大模型根据评分细则进行打分或进行成对比较。
- 特点:极其灵活,能处理细微差别和带有主观性质的标准。
- 缺点:自身具有非确定性,需要不断的人工校准。
- 人类评分员(Human graders):人工审核。
- 特点:代表“黄金标准”,保真度最高。
- 缺点:极其缓慢且昂贵。通常用于小规模抽查、A/B 测试或为模型评分器做校准对齐。
3. 两类不同目标的评估集
评估不应一成不变,文章建议将其分为两种不同目的的测试集:
- 能力评估(Capability Evals):“这个 Agent 究竟能做到什么?”。这类评估通常面临最具挑战性的前沿任务,初始通过率往往很低,它为你提供了一座“需要攀登的山峰”。
- 回归评估(Regression Evals):“它原来的功能还没坏吧?”。当 Agent 掌握了能力评估中的某项技能后,该测试用例就会“毕业”进入回归测试集。这里的通过率应保持在近乎 100%,它的作用是作为安全网,防止你在优化新功能时把老系统搞崩溃。
4. 解决“非确定性”的指标设计
由于 Agent 每次运行的轨迹可能不同,简单的单次测试无法反映真实水平。文章推荐针对性地使用不同指标:
- pass@k:在 $k$ 次尝试中只要成功 1 次就算通过。用于衡量模型能力的“上限”和潜力。
- pass^k(连续成功):连续 $k$ 次尝试必须全部成功。用于衡量模型在生产环境中行为的“绝对可靠性”。
5. 高价值的最佳实践与建议
- 尽早开始,以评测驱动开发(Eval-driven development):不要等系统庞大时再建评估。建议初期先手写 20-50 个核心任务,明确“成功的定义”(类似测试驱动开发 TDD)。等待的时间越长,构建评估体系的难度就越大。
- 务必阅读执行日志(Read the transcripts!):这是验证评估质量的唯一方法。不要只看最终的评分,你必须去看 Agent 的执行轨迹。很多时候评估跑出了“失败”,实际上是因为 Agent 找到了比参考答案更好、更聪明的解法,只是评分器没有预料到。
- 构建正反平衡的测试集:不要只测试 Agent“应该做什么”(例如:遇到不懂的问题应该去搜索网页),也要测试它“不该做什么”(例如:问它常识问题时不要过度搜索)。偏科的评估会训练出行为极端的 Agent。
- 区分生成内容与执行路径:通常来说,评估 Agent 最终产生了什么结果(Outcome),比评估它具体通过什么路径完成(Transcript/Path)更加有效且稳健。
总结:
Anthropic 的这篇文章指出,AI 行业的壁垒正在发生转移。模型、提示词和数据正在商品化,而系统性、科学地衡量 Agent 性能的“评估能力”,才是区分一个玩具 Demo 和成熟商业产品的真正护城河。建立可靠的评估体系(Evals)虽然前期枯燥且投入大,但它的价值会在整个 AI Agent 的生命周期中产生复利。
Comments NOTHING